Vision with Core ML
Vision with Core ML
WWDC 2018
The Storyline
Create an app helping shoppers identify item
- Train a custom classifier
- Build an iOS app
- Keep an eye on pitfalls

Our Training Regimen
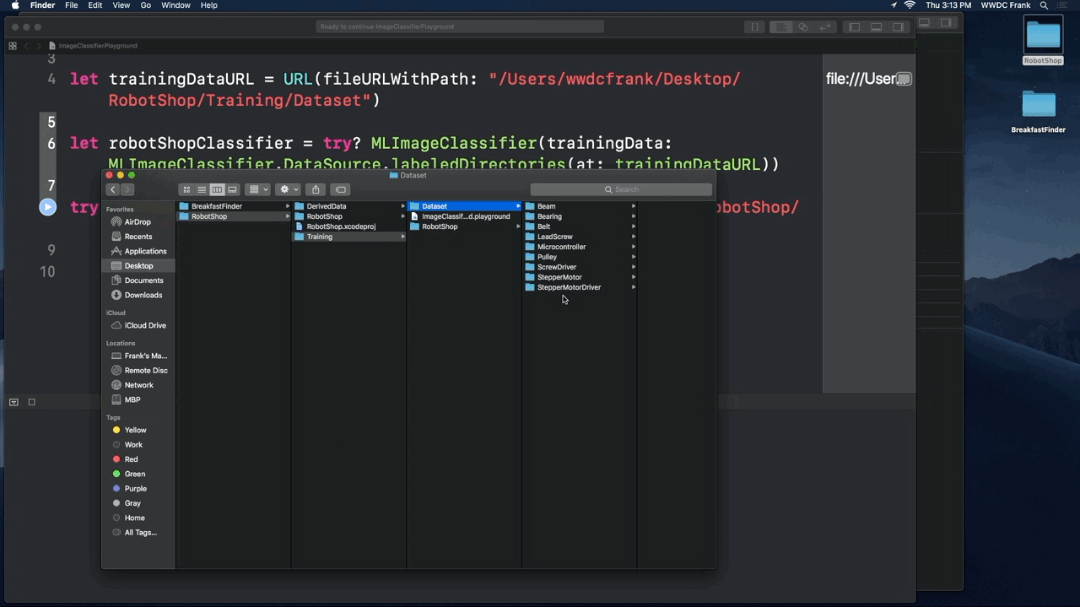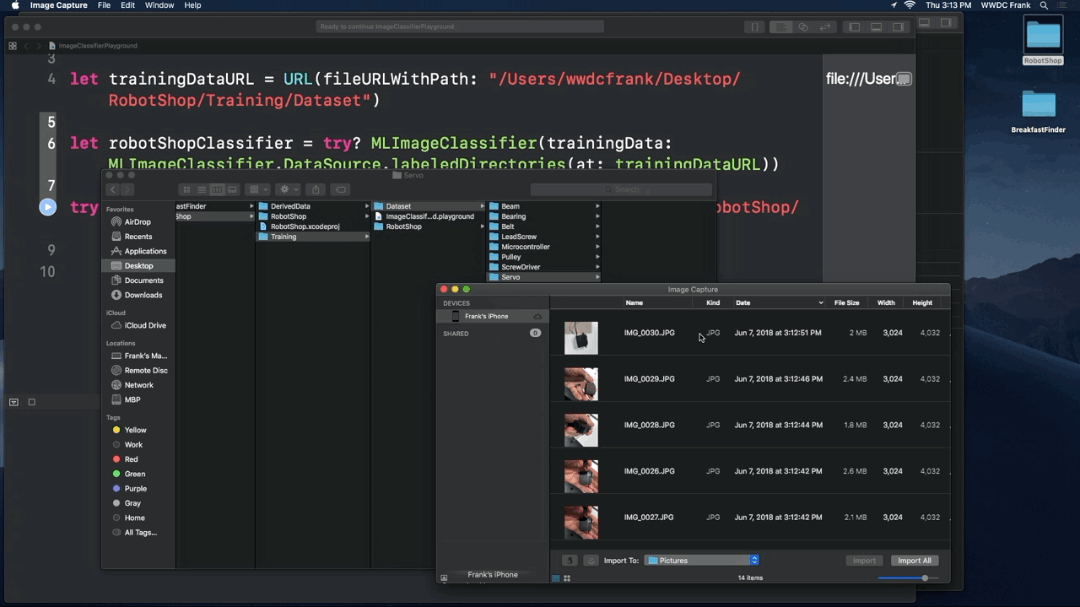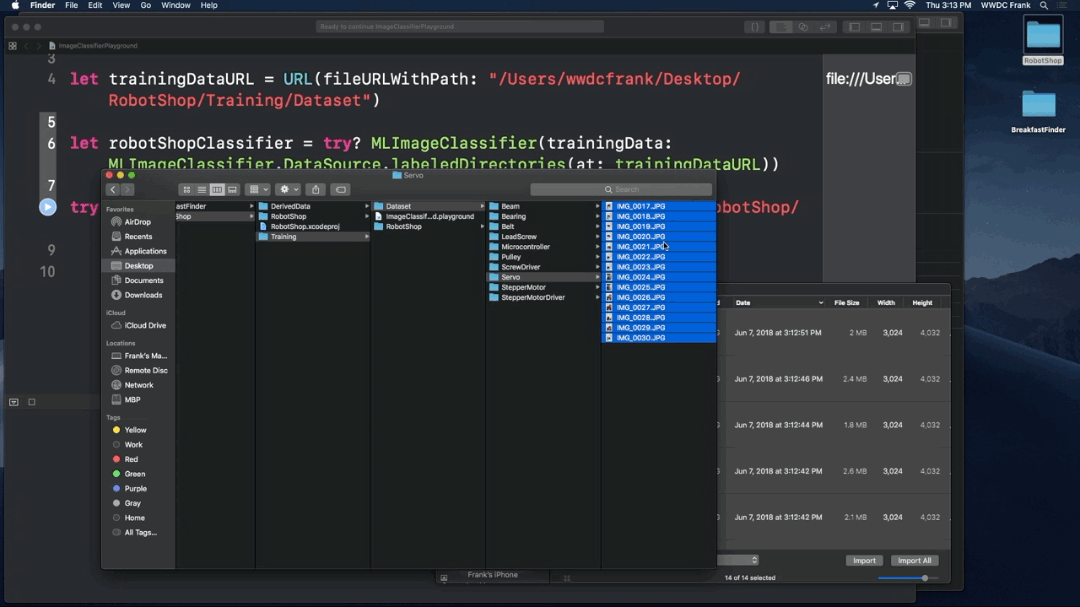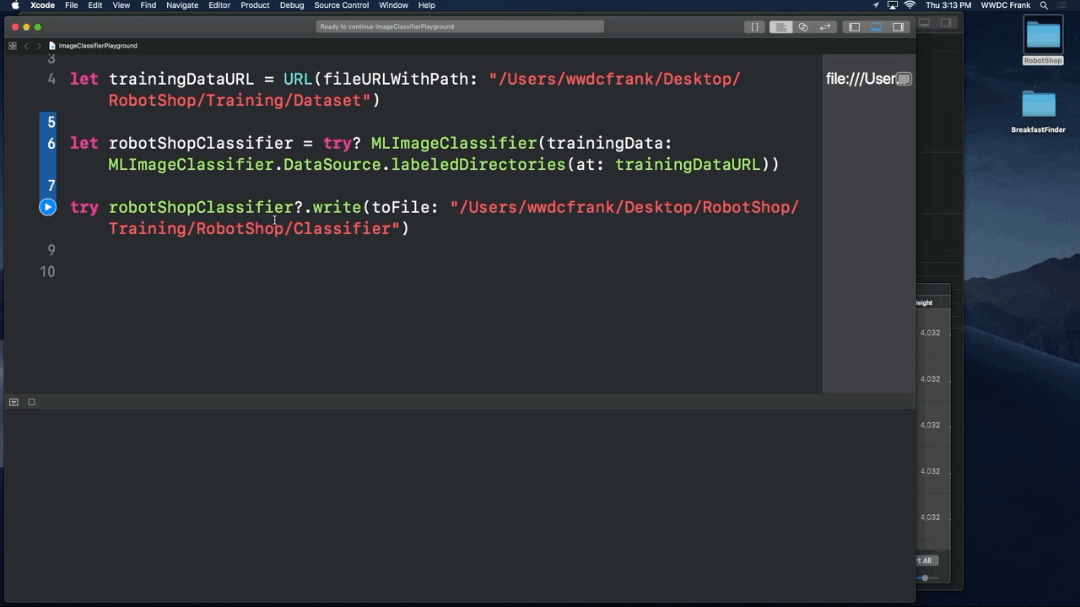
- Take pictures
- Sort into folders — the folder names are used as labels
- How much data do I need
- Minimum of 10 per category but more is better
- Highly imbalanced datasets are har to train - Augmentation adds some robustness on top of it but doesn’t replace variety

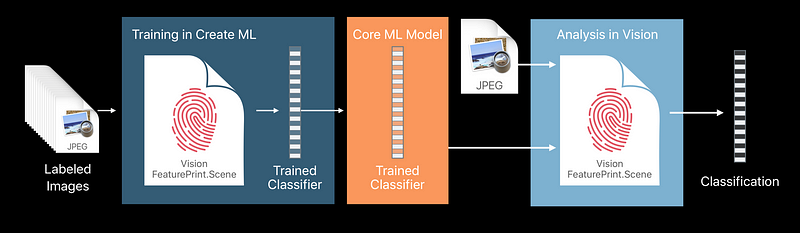
Under the Hood
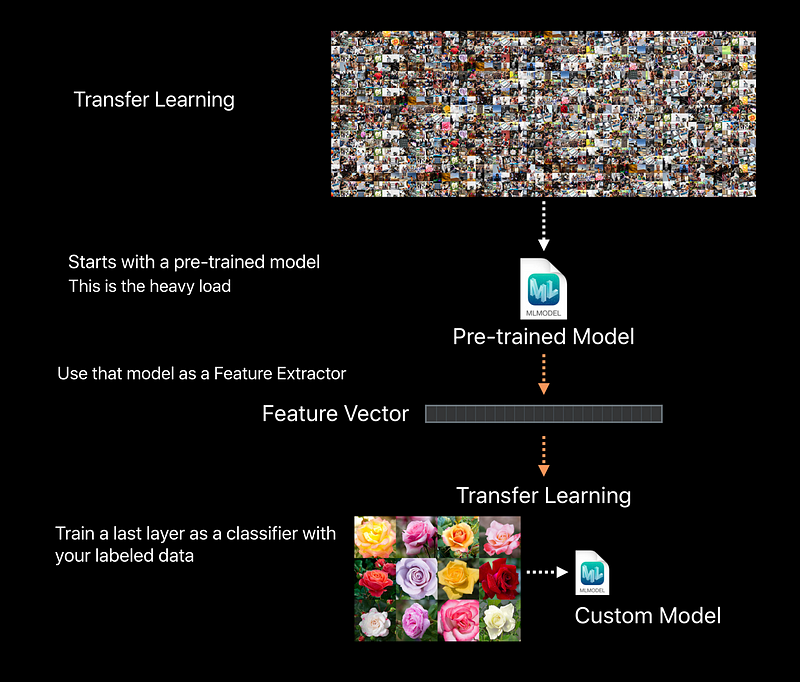
Vision FeaturePrint.Scene
Vision Frameworks FeaturePrint for Image Classfication
- Available through ImageClassifier training in Create ML
- Trained on a very large dataset
- Capable of predicting over 1000 categories
- Powers user facing features in Photos
- Continuous improvement (You might want to retrain in the future)
- Already on device
- Smaller disk footprint for your custom model - Optimized for Apple devices

Refining the App
Only classify when needed !
- Don’t run expensive tasks when not needed
- AM I holding still?
- Using registration
- Cheap and fast
- Camera holds still
- Subject is not moving VNTranslationalImageRegistrationRequest

Always have a backup plan
- Classifications can be wrong
- Event when confidence is high > plan for it
- Alternative identification
- Barcode reading

Demo
- Using Registration for Scene Stability
- Use the
VNSequenceRequestHandlerwithVNTranslationalImageRegistrationRequest - Compare against previous frame
sequenceRequestHandler.perform([request], on: previousBuffer!) - Registration is returned as pixels in the
alignmentObservation.alignmentTransform - Analyze only when scene is stable
- Create an
VNImageRequestHandlerfor the current frame and pass in the orientation - Perform Barcode and Image Classification together
try imageRequestHandler.perform([barcodeDetection, imageClassification]) - Manage your buffers
- Some Vision requests can take longer
- Perform longer task asynchronously
- Do not queue up more buffers than the camera can provide
- We only operate with a one deep queue in this example
1. Take photos

2. Make a Machine Leaning Model
Using the storyboard
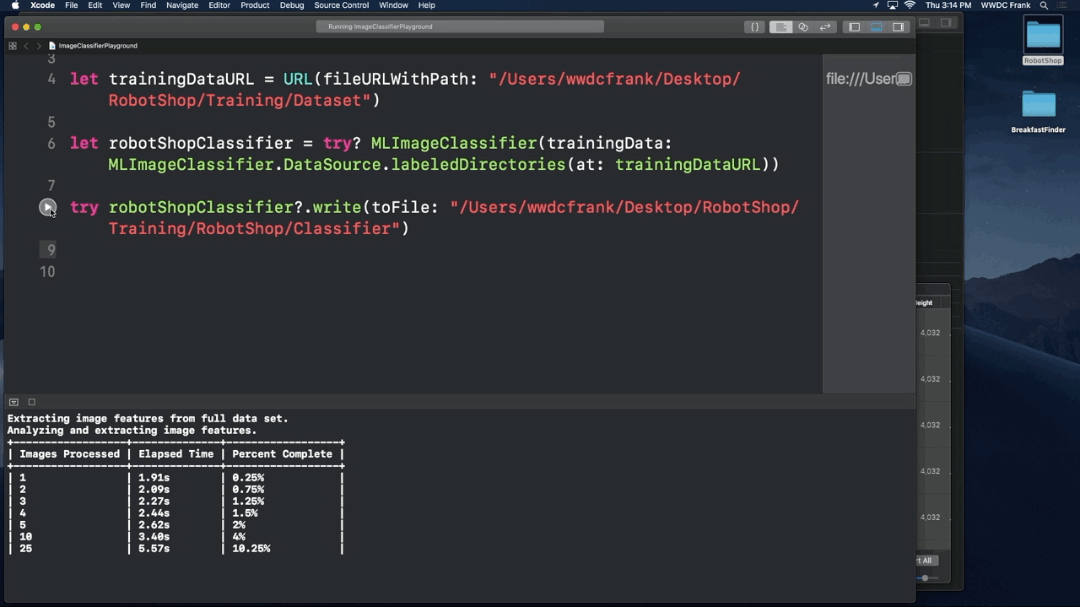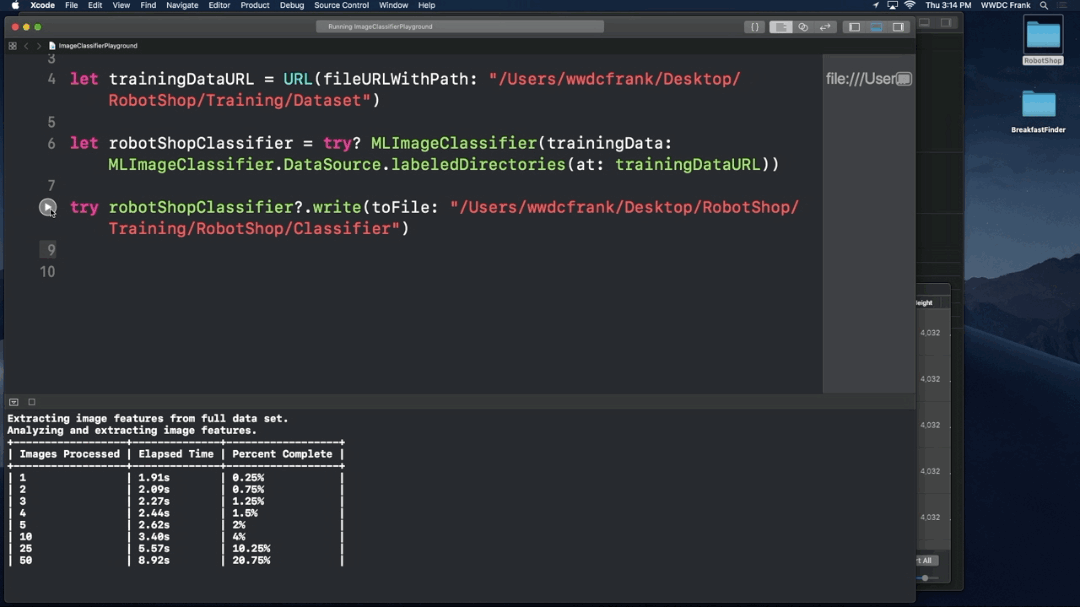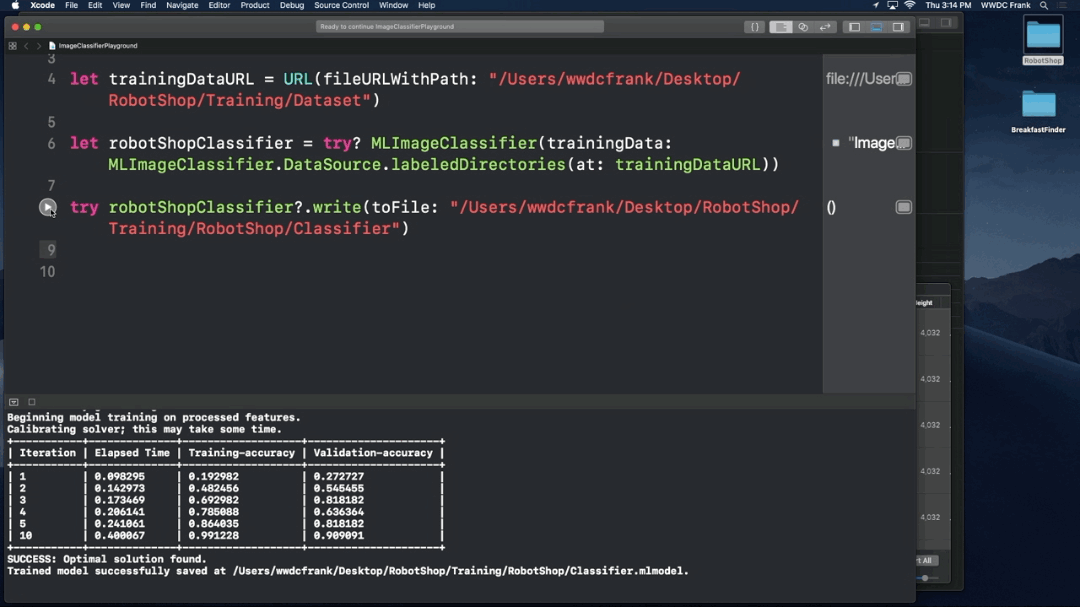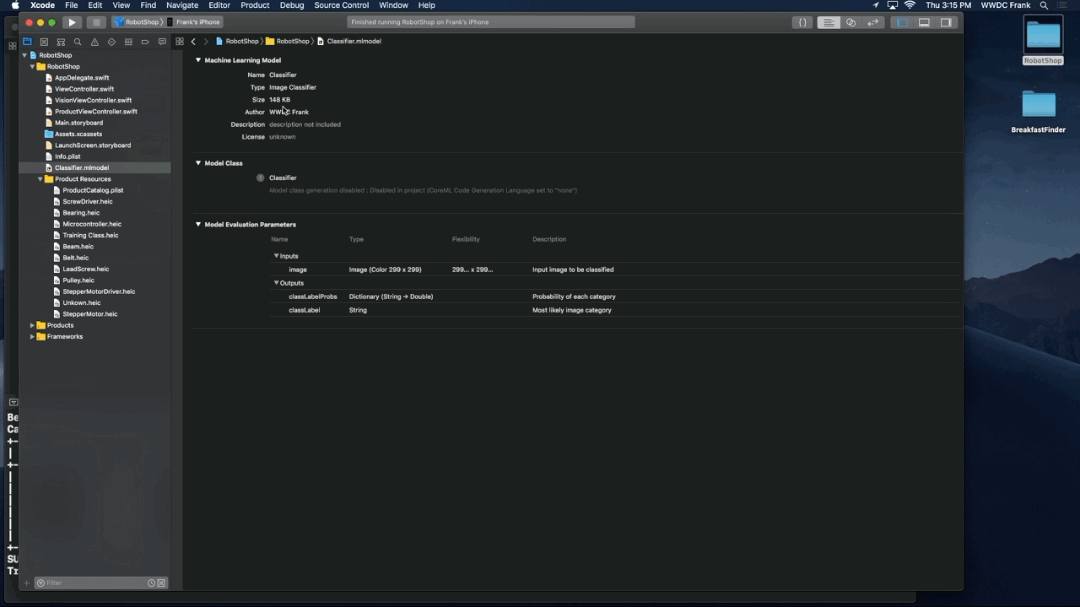
3. Settings
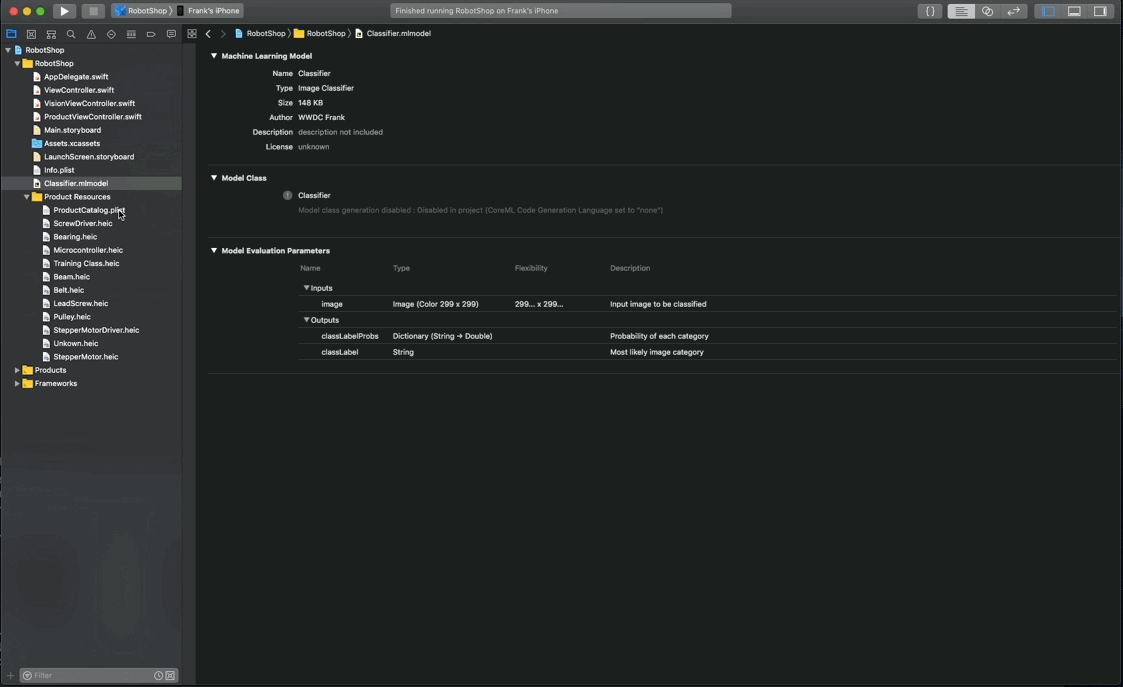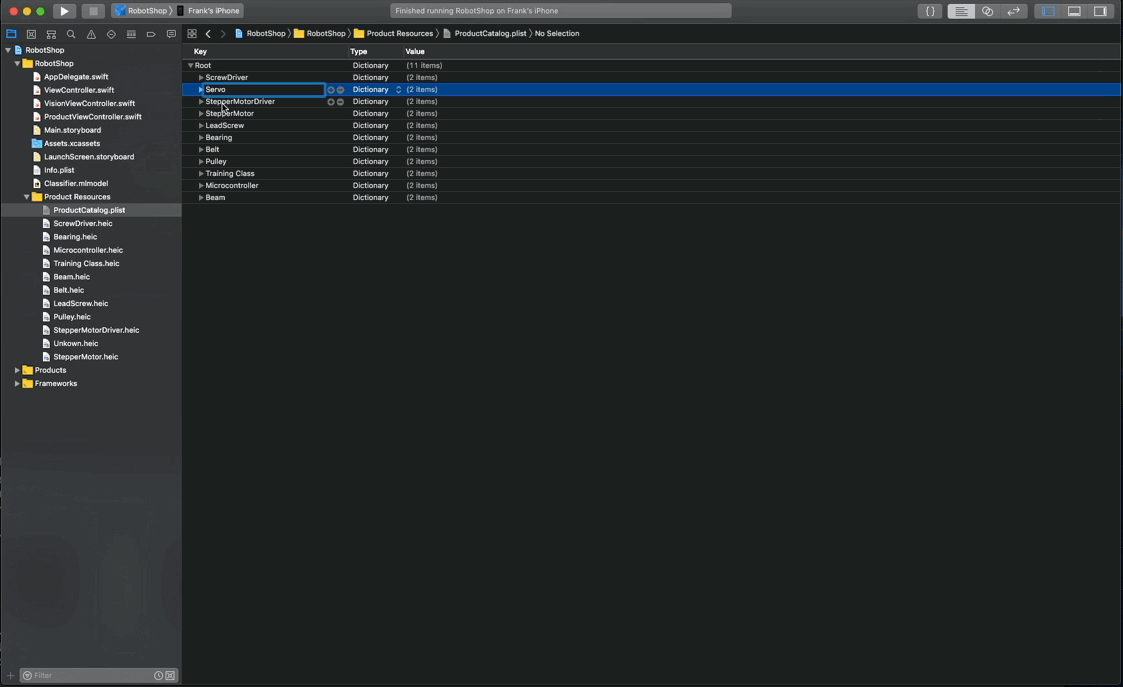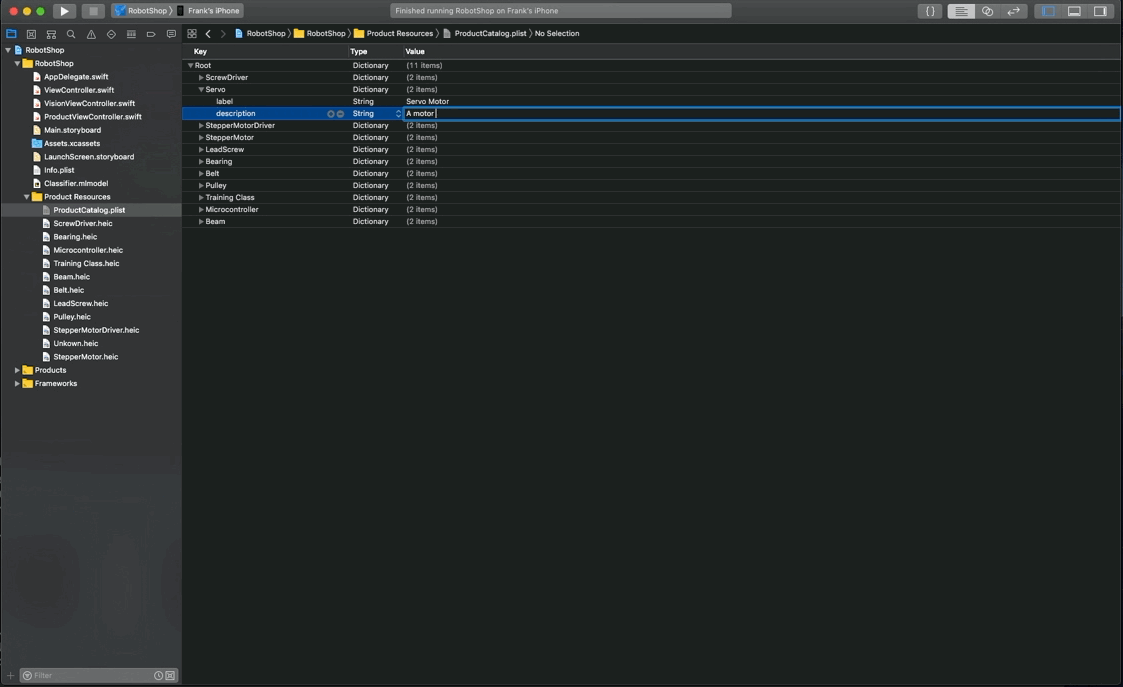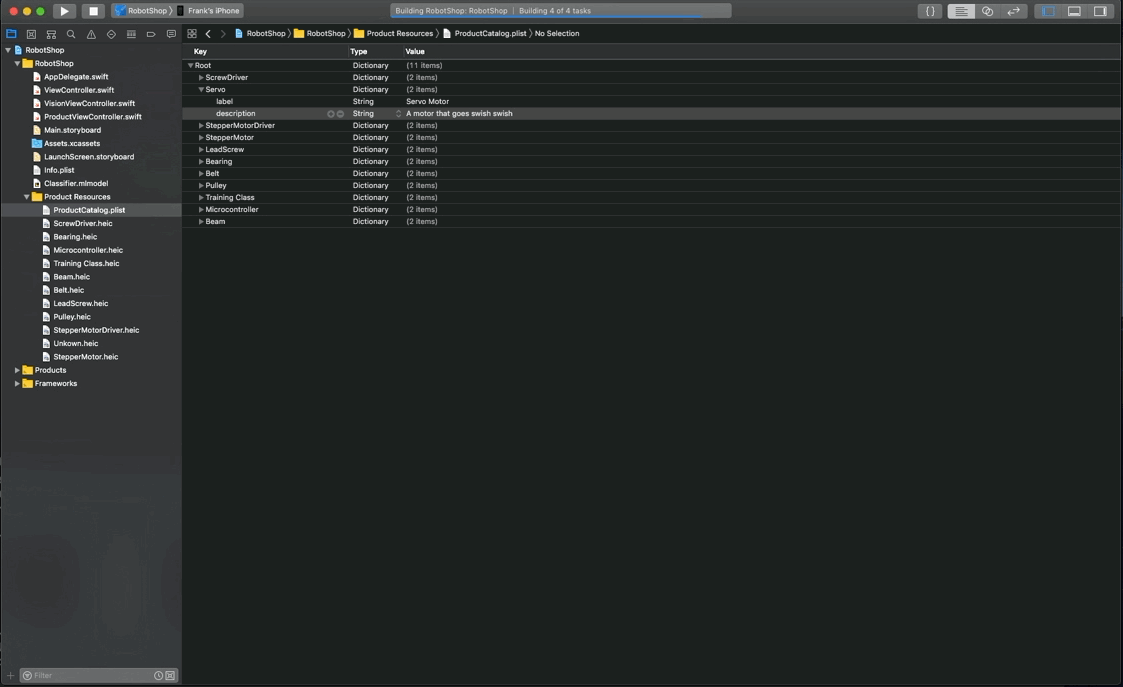
4. Run

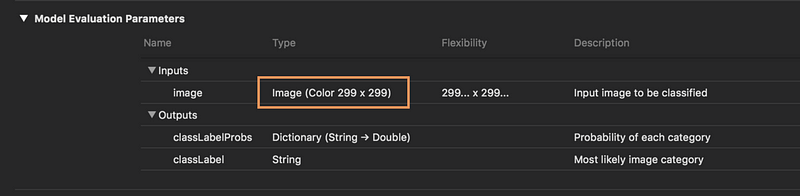
Why not use just Core ML?
- Vision does all the scaling and color conversion for you
Object Recognition
- YOLO (You Only Look Once)
- Fast Object Detection and Classification
- Label and Bounding Box
- Finds multiple and different objects - Train for custom objects
- Training is more involved than ImageClassifier
Demo

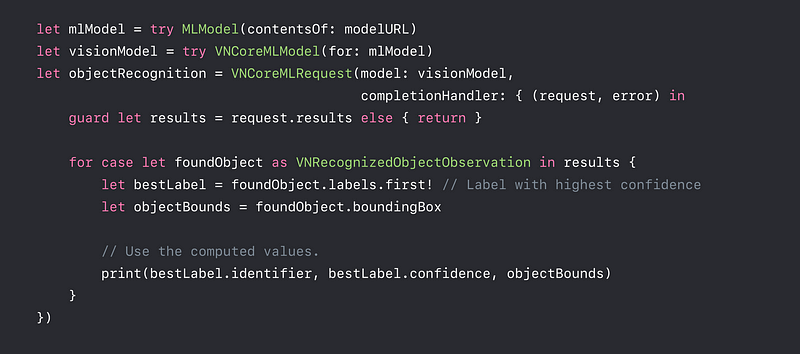
VNRecognizedObjectObservation
- Result of a
VNCoreMLModelRequest - New observation subclass
VNRecognizedObjectObservation - YOLO based models made easy
Tracking
! Tracking is faster and smoother than re-detection !
- Use tracking to follow a detected object
- Tracking is a lighter algorithm
- Applies temporal smoothing
Image Orientation
- Not all algorithms are orientation agnostic
- Images are not always upright
- EXIF orientation defines what is upright
- When using a URL as input Vision reads the EXIF orientation from file - Live from a capture feed
- Orientation has to be inferred fromUIDevice.current.orientation
- Needs to be mapped to aCGImagePropertyOrientation
Vision Coordinate System
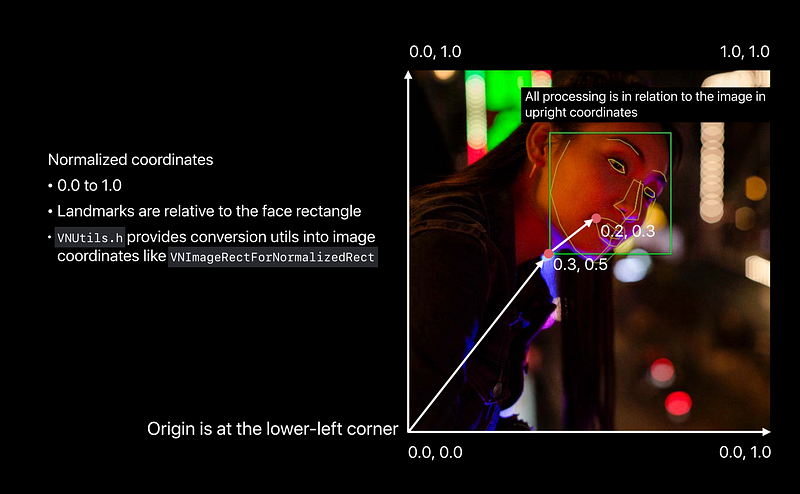
Confidence Score
- A log of algorithm can express how certain they are about the results
- Confidence is expressed 0 ~ 1.0
- The scale is not uniform across request types
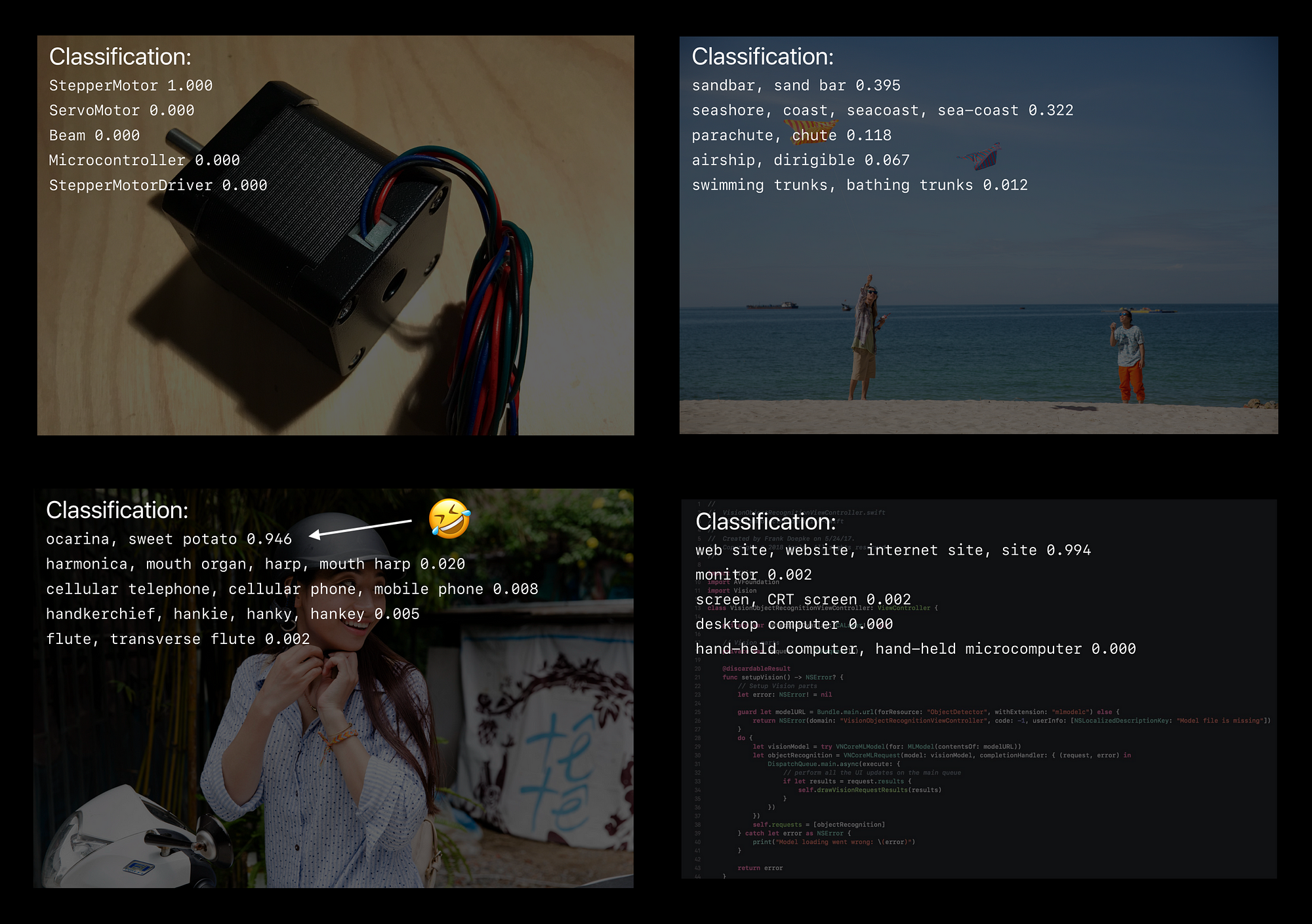
Confidence Score Conclusion
- Does 1.0 mean it’s certainly correct ????
- It fulfilled the criteria of the algorithm but our perception can differ - Where the threshold is depends on the use case
- Labeling requires high confidence — Observe how your classifier behaves
- Search might want to include lower confidence scores as they are probable