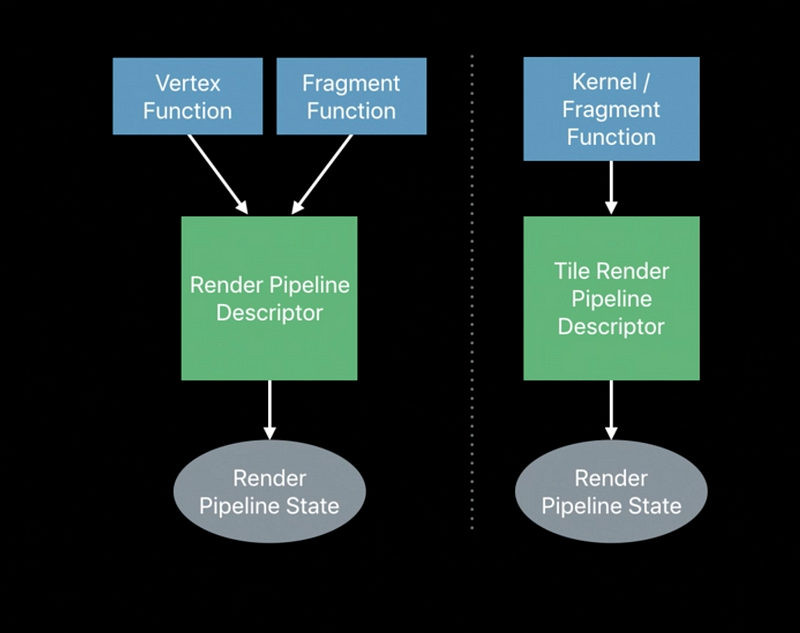
New descriptor type - 1 function can be bound - No blend state
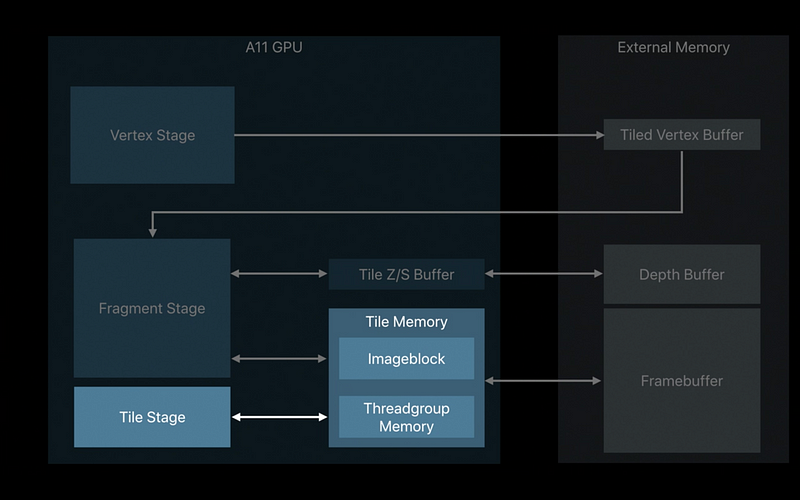
Tile piplines can be built from - Kernel functions - Fragment functions
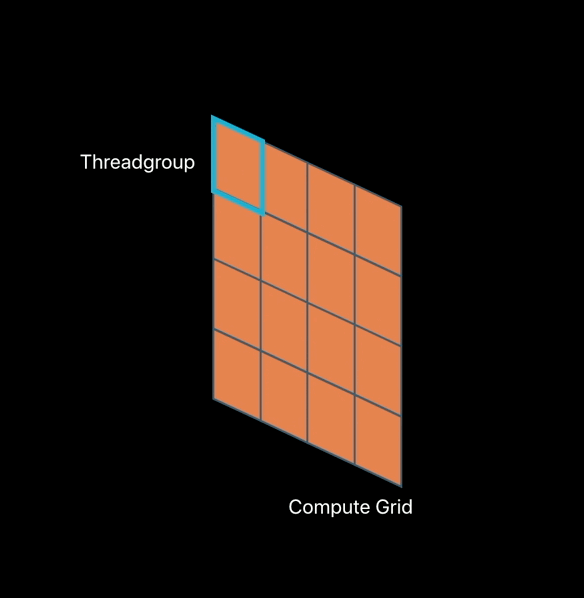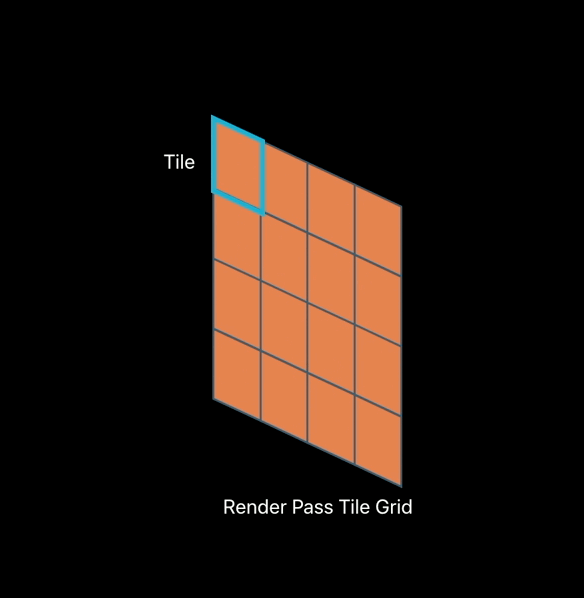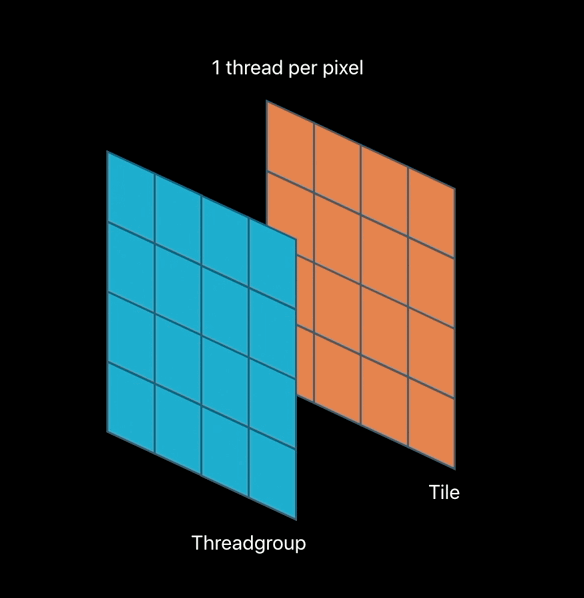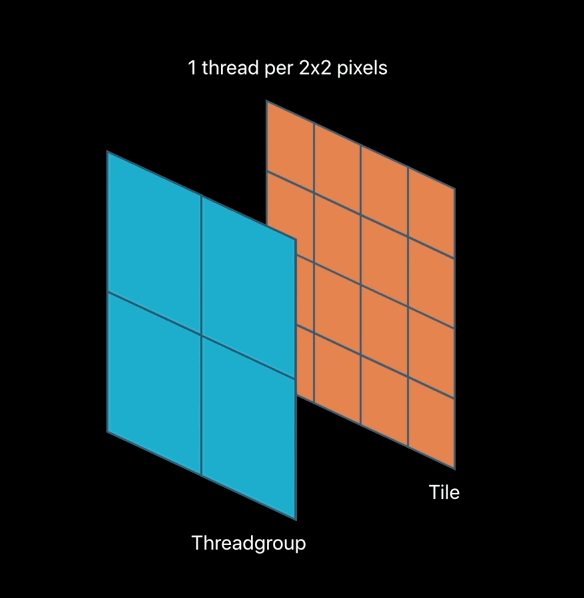
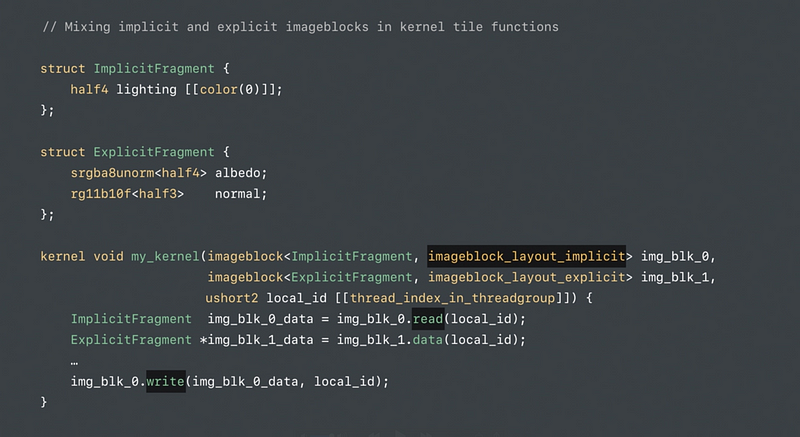
Imageblocks in Tile Pipelines
Kernel-based tile pipelines access: - All (x, y) locations - Explicit imageblock elements by reference - Implicit imageblock elements by value
Fragment-based title pipelines access: - Implied (x,y) location - Explicit imageblock elements by value - Implicit imageblock elements by value
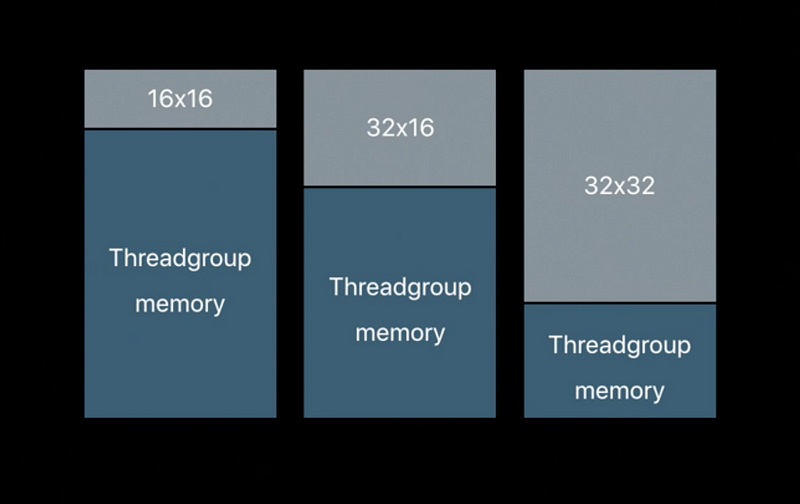
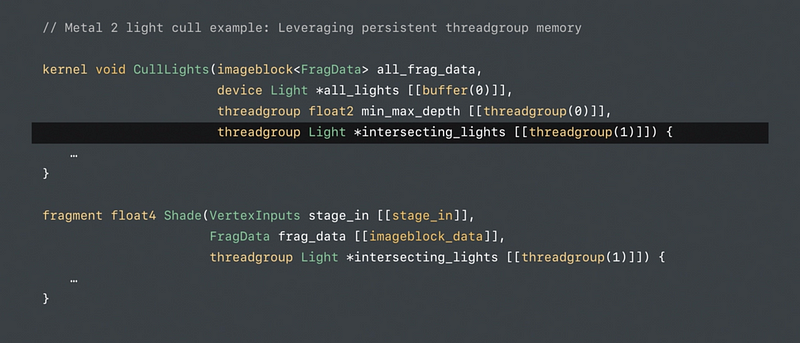
Threadgroup Memory Persistence
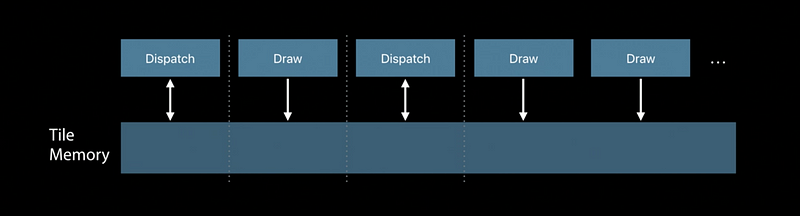
Render pass imageblocks persist for lifetime of tile
Render pass threadgroup memory also persists for lifetime of tile
Threadgroup memory well suited for tile constant data
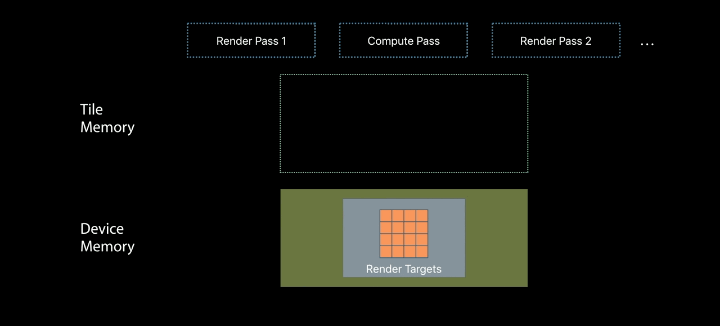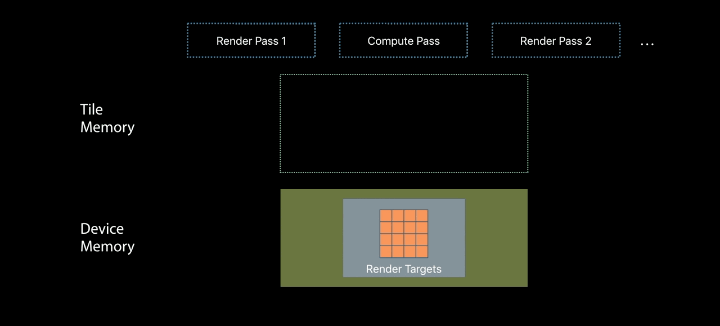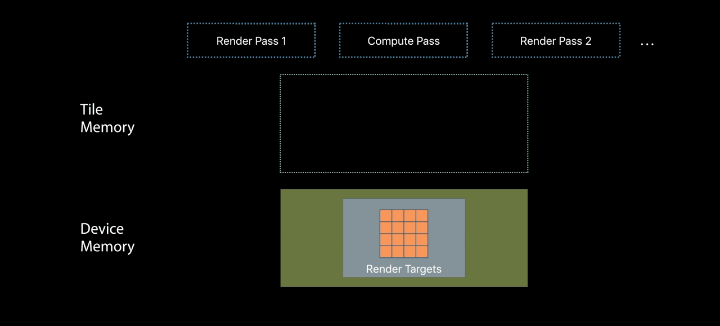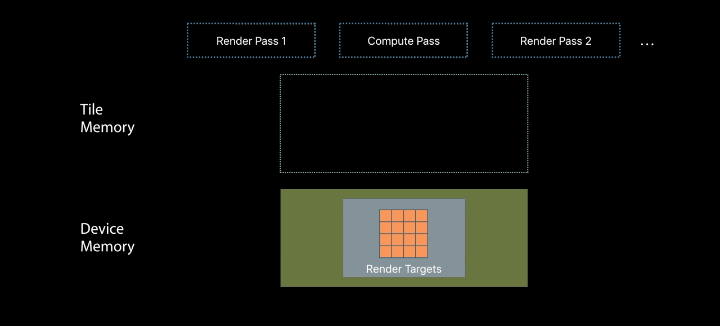
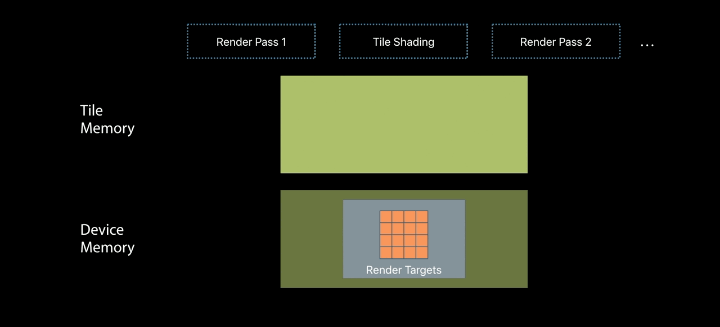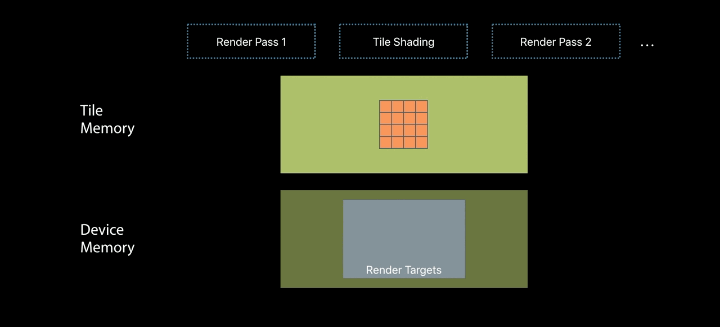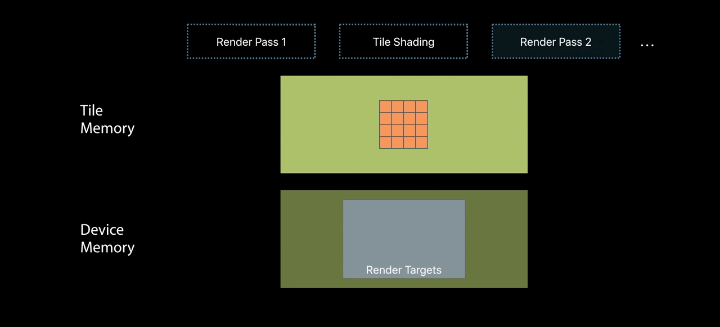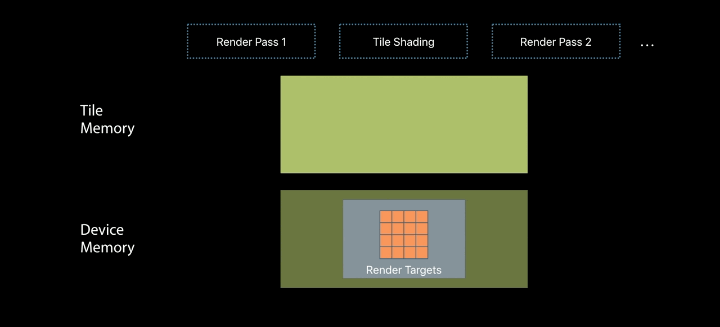
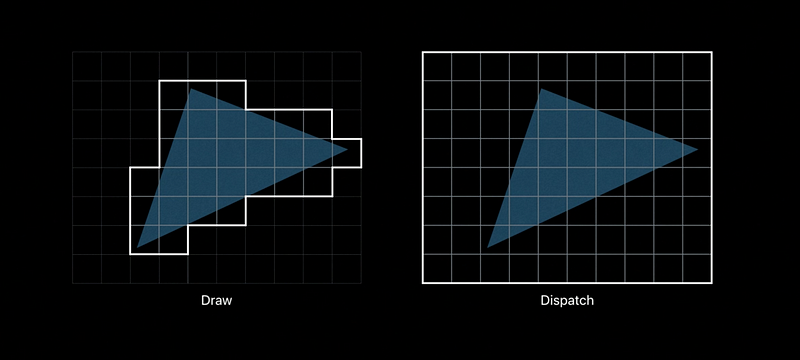
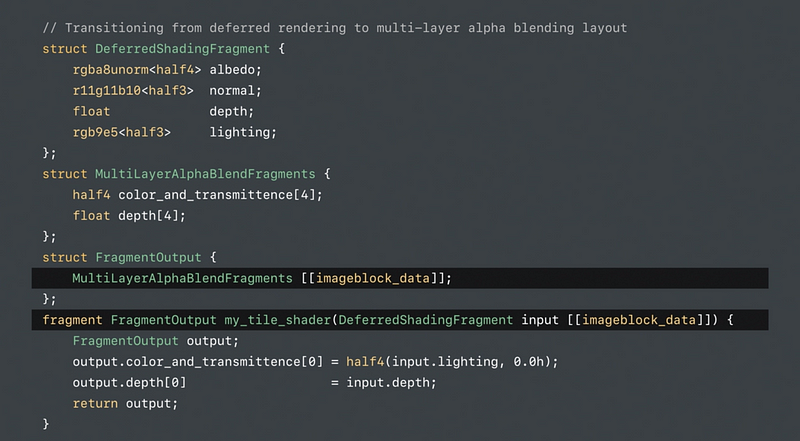
Repurposing Tile Memory
The shading enables merging compute and render passes
Use fragment-based tile pipelines to transition between memory layouts - The barriers ensure atomicity across pixels - Value semantics ensure atomicity within pixels