Metal for Game Developers
Metal for Game Developers
WWDC 2018
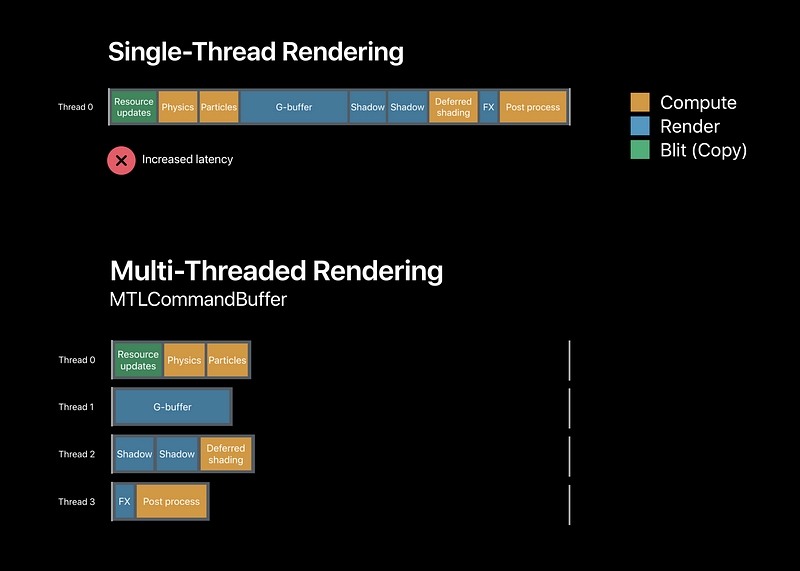
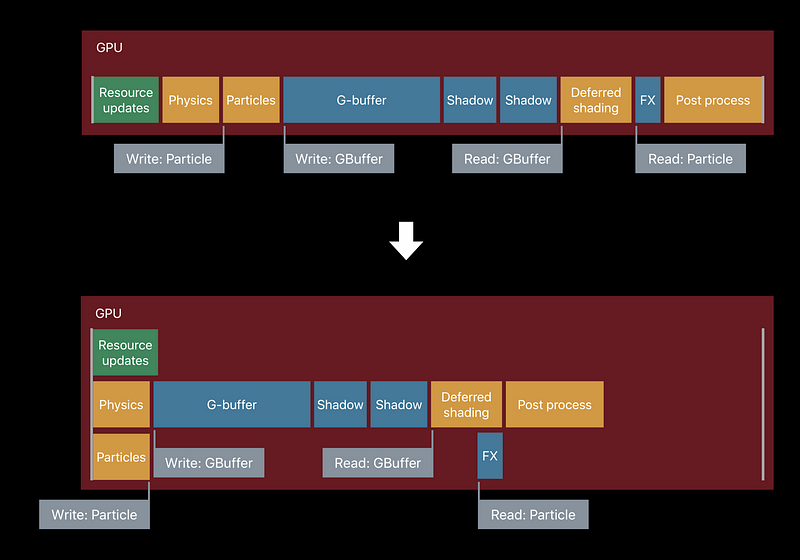
Harnessing Parallelism
- Scalable multi-threaded encoding is key
- Metal makes multi-threaded CPU command generation easy an fast
- Metal automatically parallelized GPU tasks
Multi-Threaded Rendering
MTLCommandBuffer
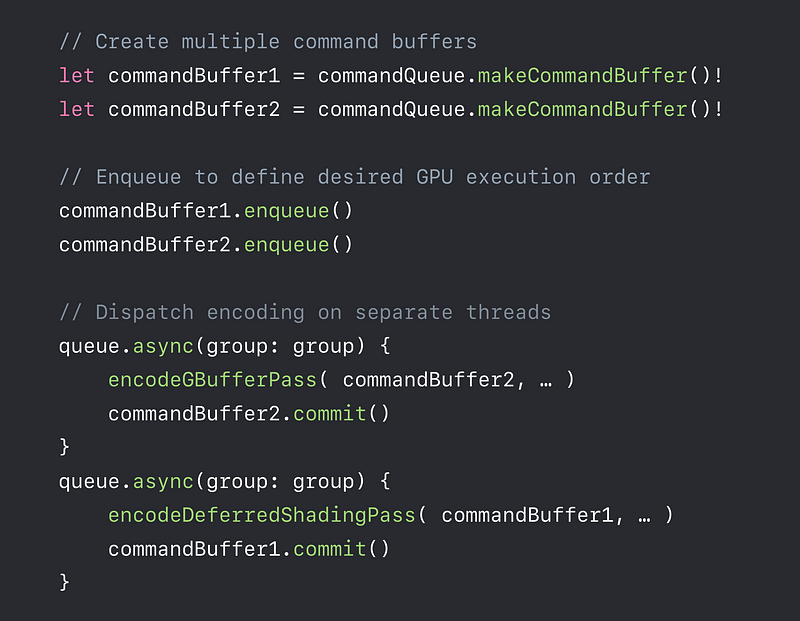
With MTLParallerRenderCommandEncoder
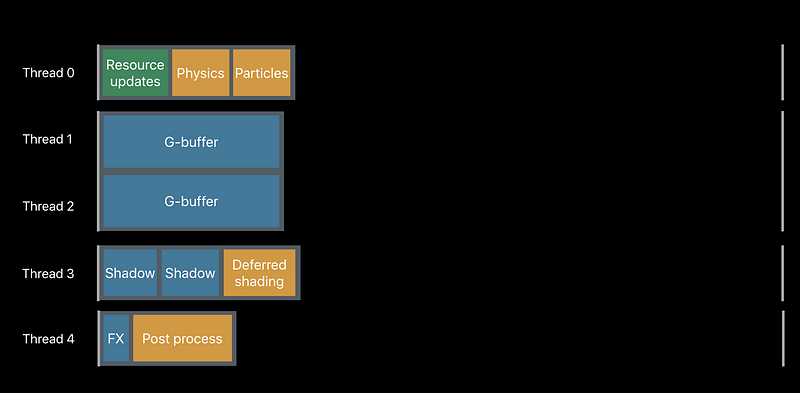
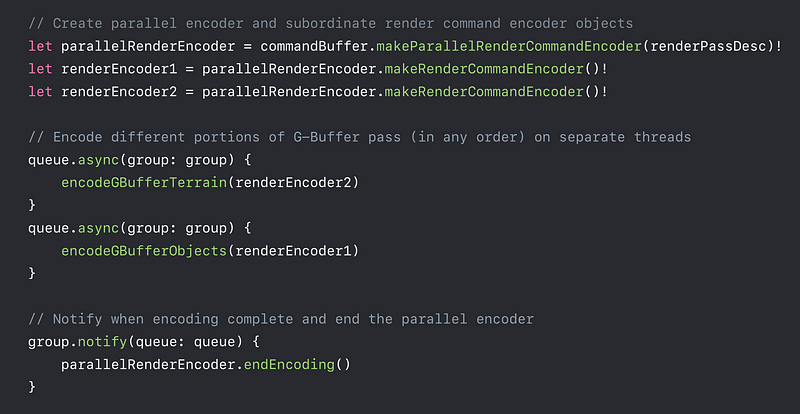
GPU Parallelism
Taking Explicit Control
- Metal offers more direct approaches for even less overhead
- Disable Metal’s automatic reference counting
- Allocate resource cheaply using heaps
- Control GPU parallelism with fences and events
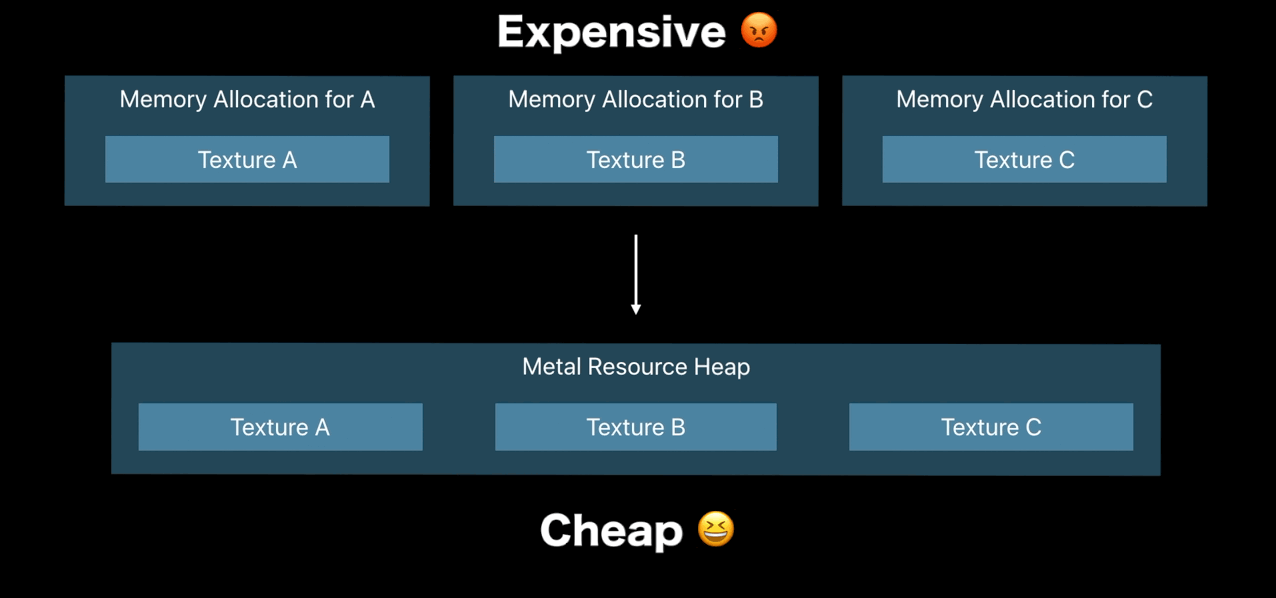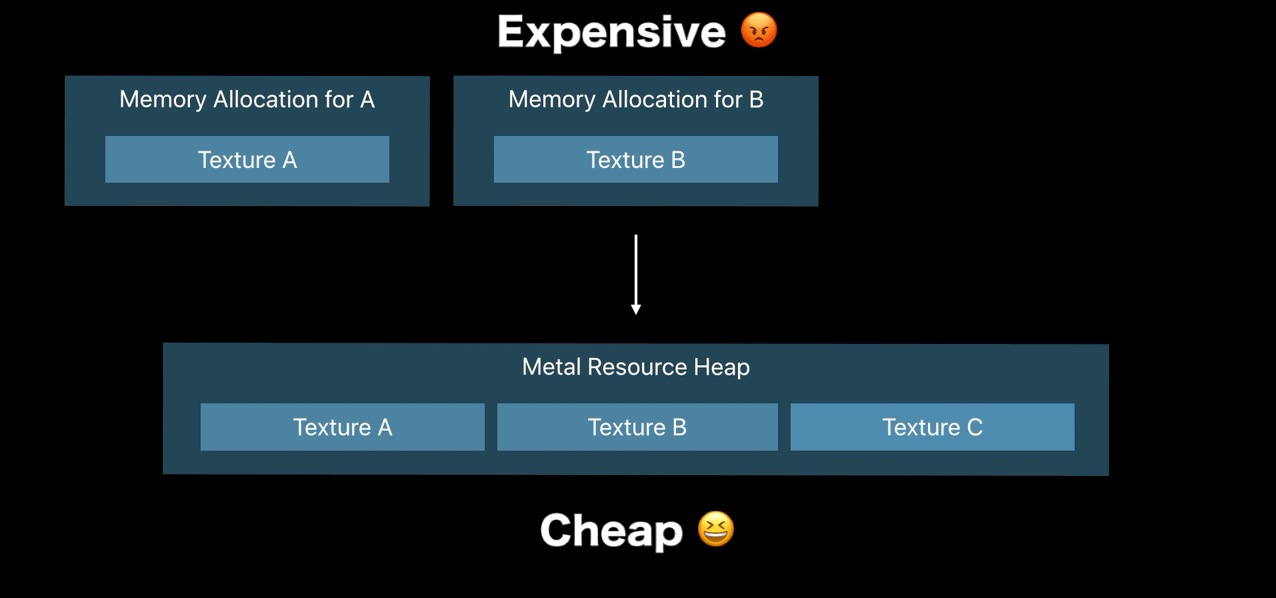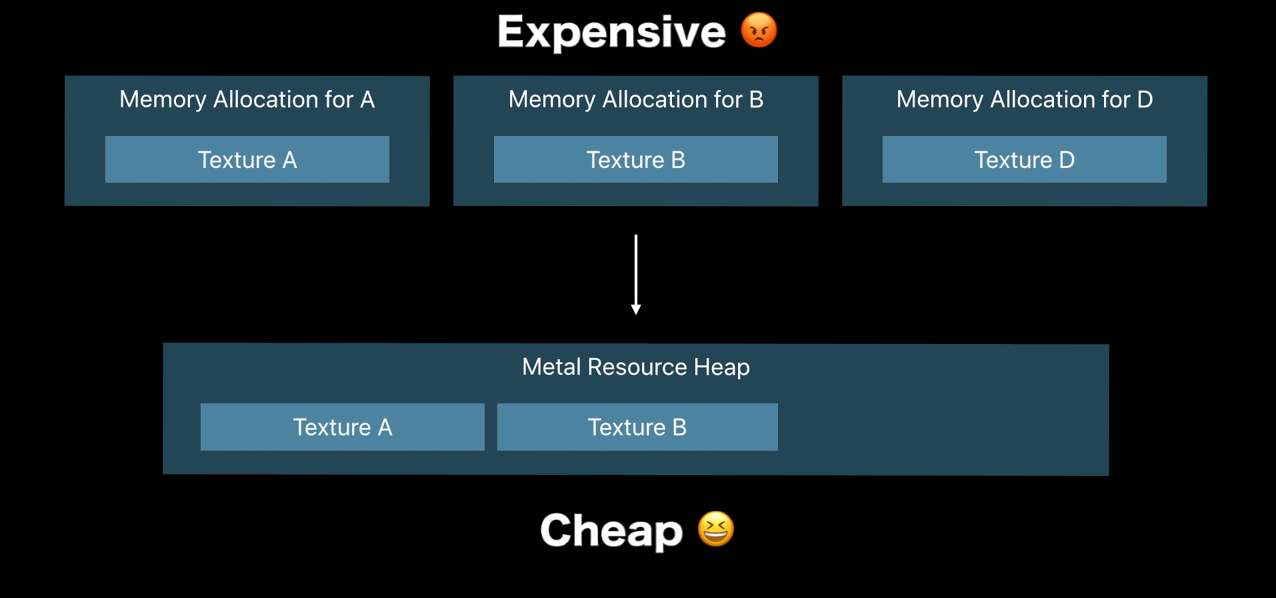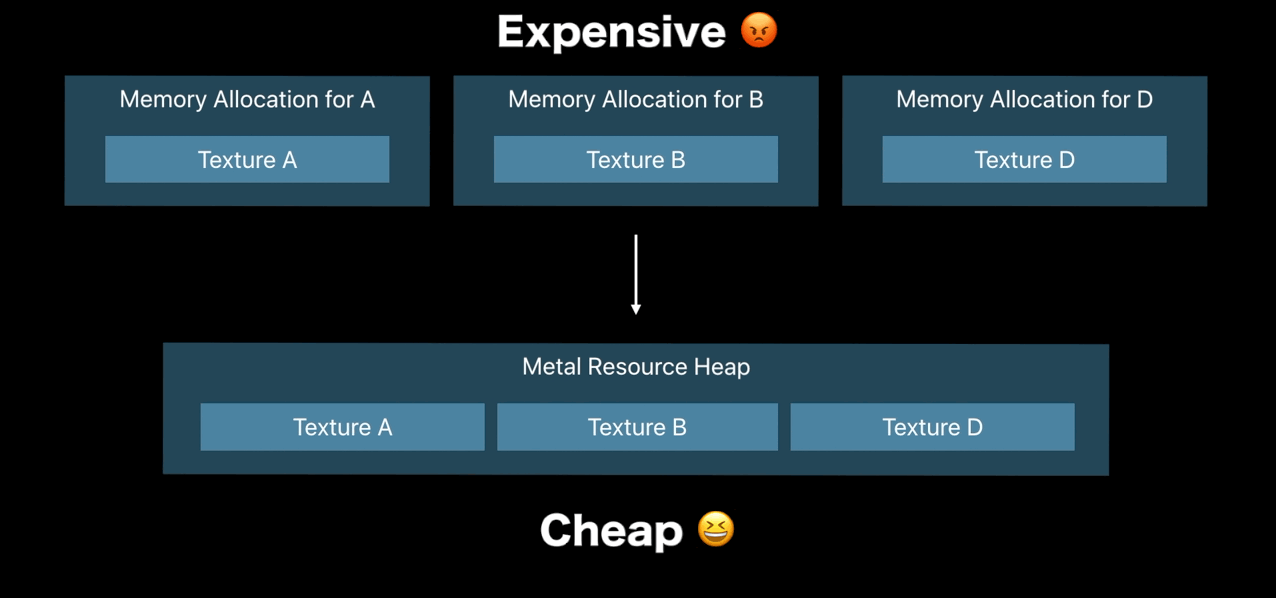
Resource Heaps
MLTHeap
- Control time of memory allocation
- Fast reallocation and aliasing of resources
- Cheaper resource binding
- Simple API
Without dependency tracking
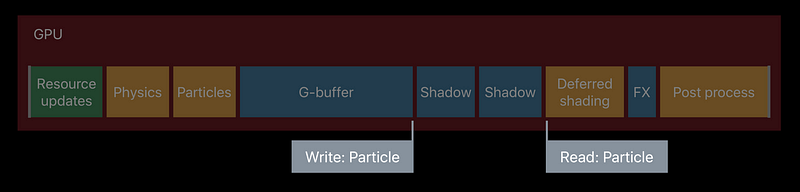
MTLFence and MTLEvent
Explicit execution order


Building GPU-Driven Pipelines
- Game are moving more and more logic onto GPU
- Efficient processing of large datasets
- Growing scene graph complexity - Metal 2 enables you to move entire render loop to the GPU
- Argument Buffers — offload parameter management
- Indirect Command Buffers — offload rendering loop
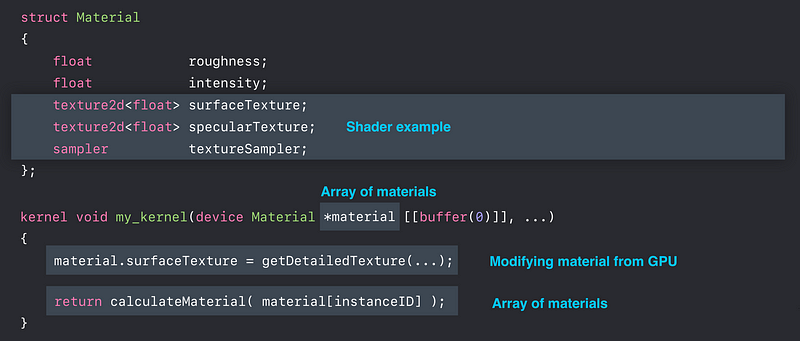
Argument Buffers
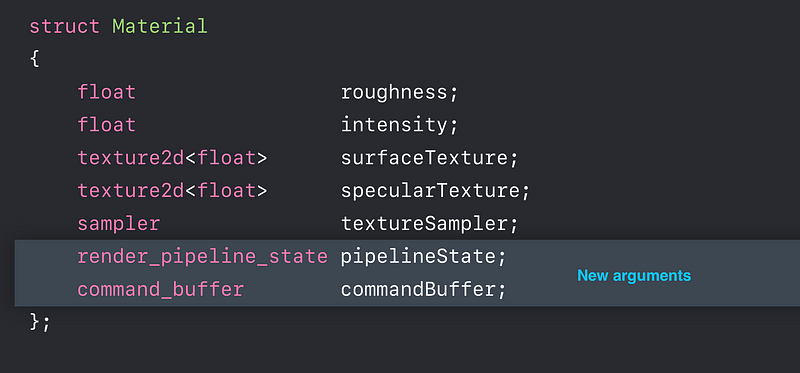
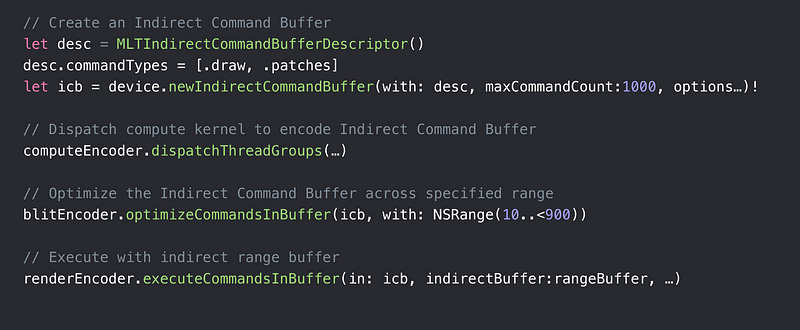
Indirect Command Buffers (ICB)
- Allow GPU to build draw calls
- Massively parallel generation of commands - Reuse ICB in multiple frames
- Modify contents - Remove expensive CPU and GPU synchronization
Game Rendering Loop
GPU Driven rendering loop

Encoding Drawcall Example
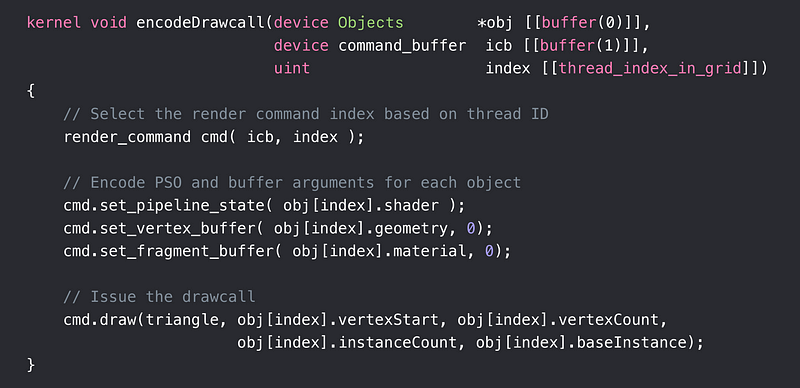
Executing ICB Example




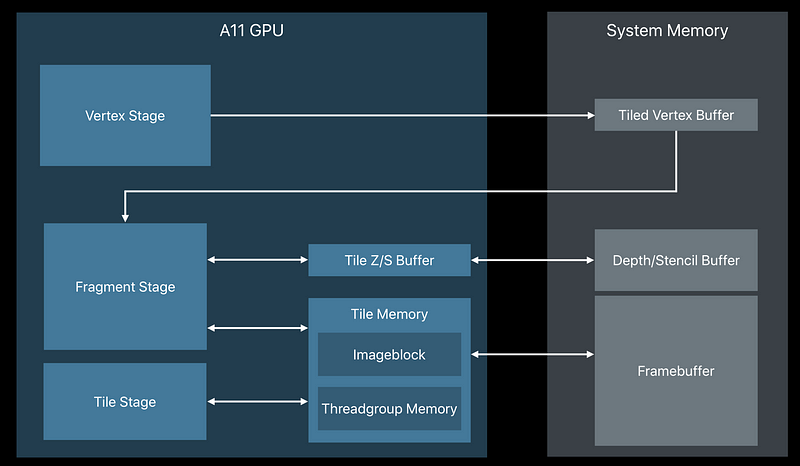
Tile-Based Deferred Rendering (TBDR)
- High performance, low power
- Tightly integrated with Metal
- A11 Bionic takes TBDR to the next level
Metal 2 Features on A11

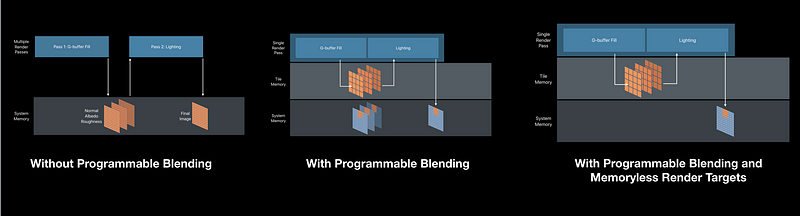
Programmable Blending
- Metal provides read-write access to pixels in tile memory
- Implement custom blend operations - Combine passes that read/write the same pixel
- Eliminates system memory bandwidth between passes
- Optimizes deferred shading
Deferred Shading
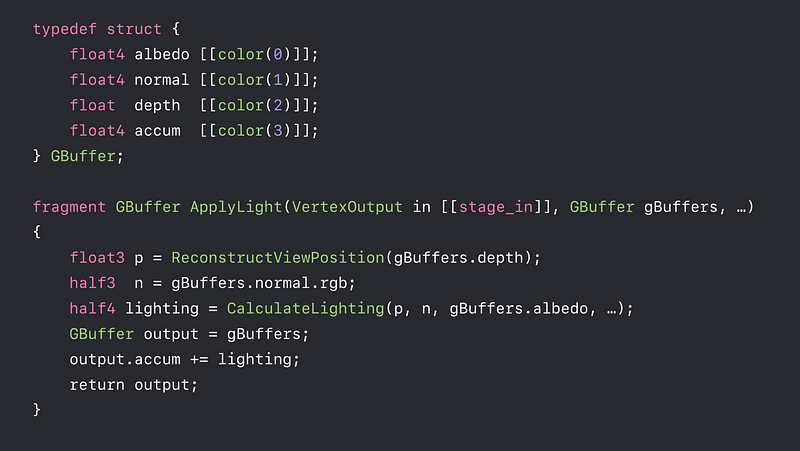
Imageblocks
- Flexible per-pixel storage in tile memory
- Layout declared in shading language - Change pixel layout within a pass
- Merge render passes with different layouts
Deferred Shading
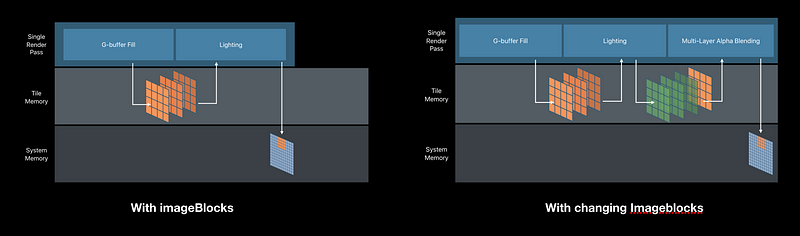
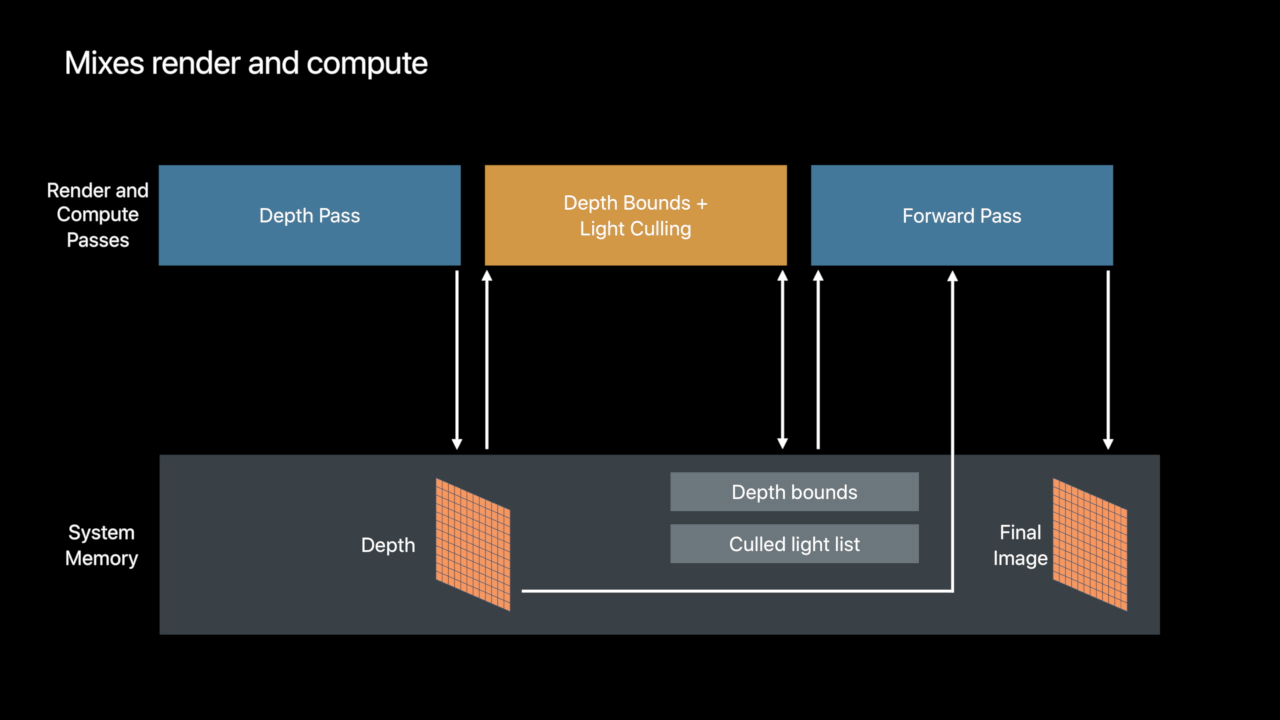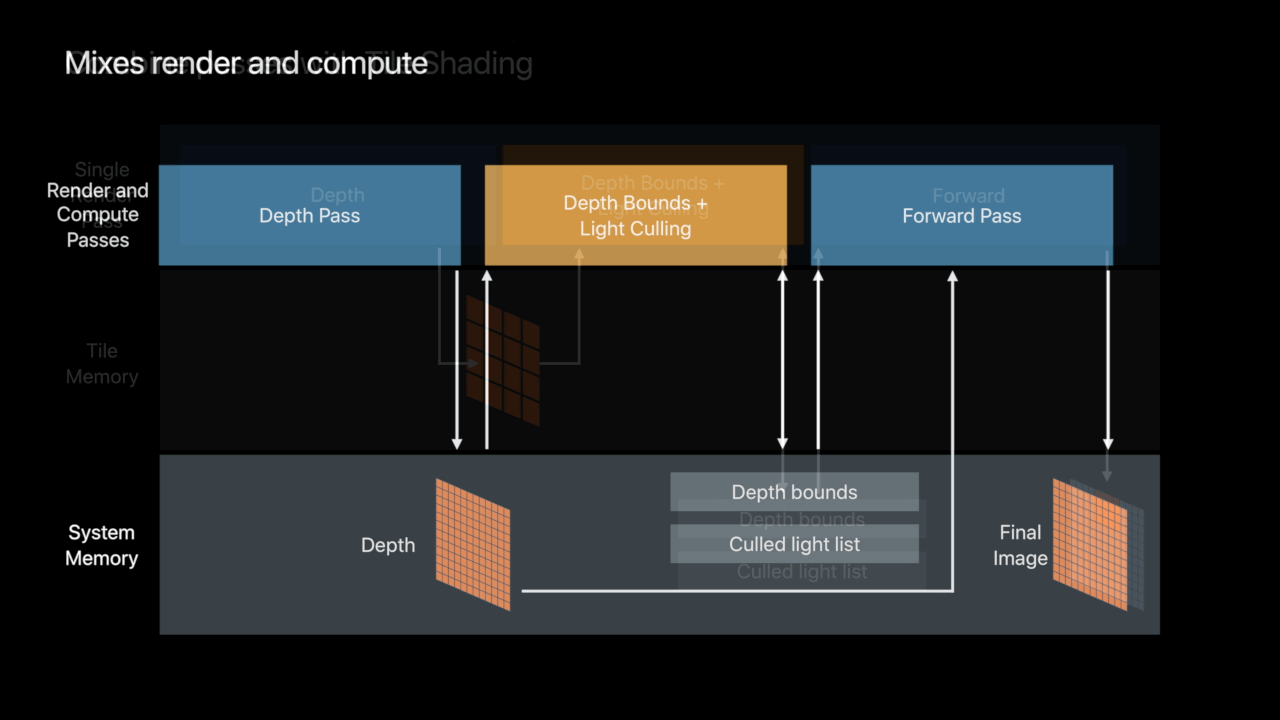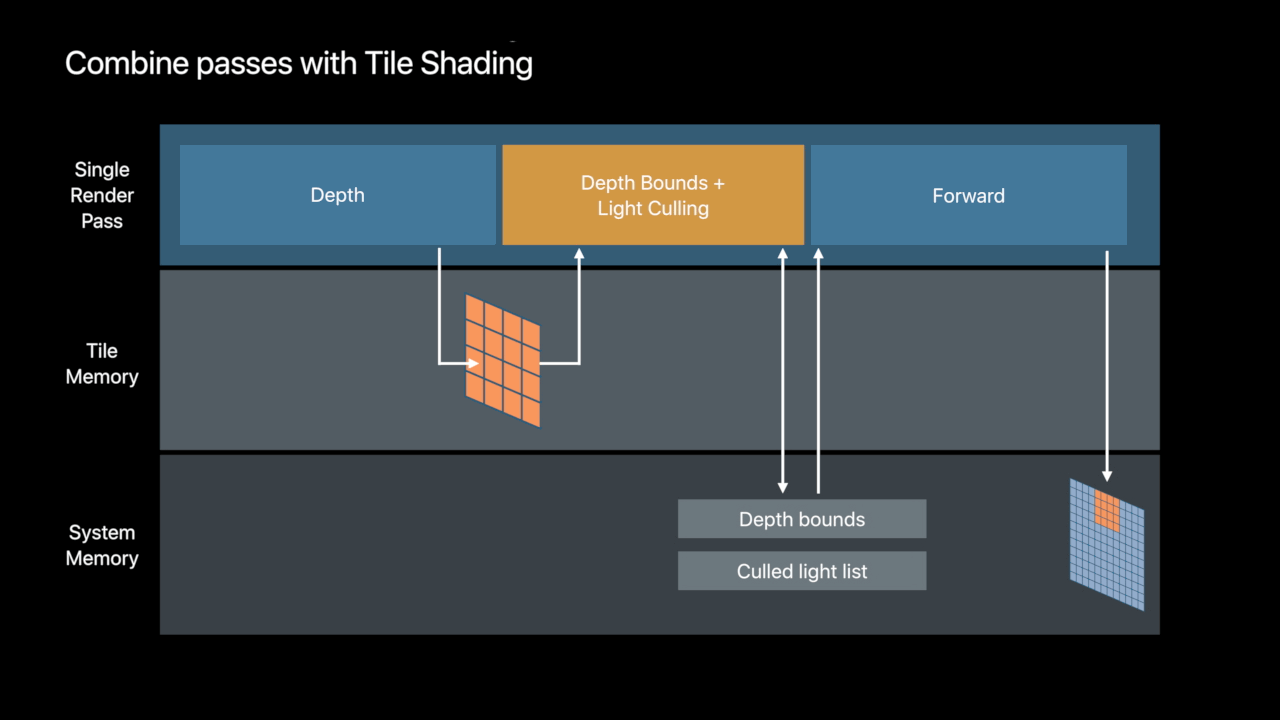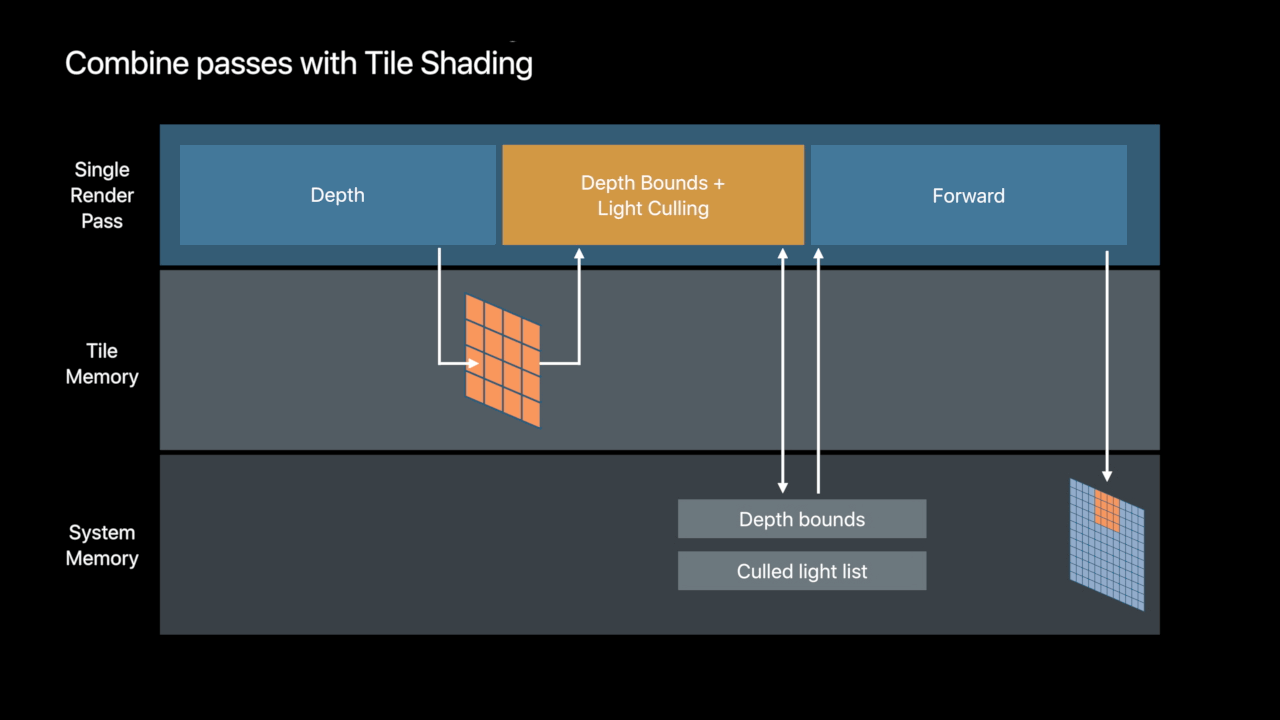
Tile Shading
- New programmable stage in the render pass
-Dispatch a configurable threadgroup per tile - Interleave render and compute processing
- Read rendering results directly from tile memory
Tiled Forward Shading
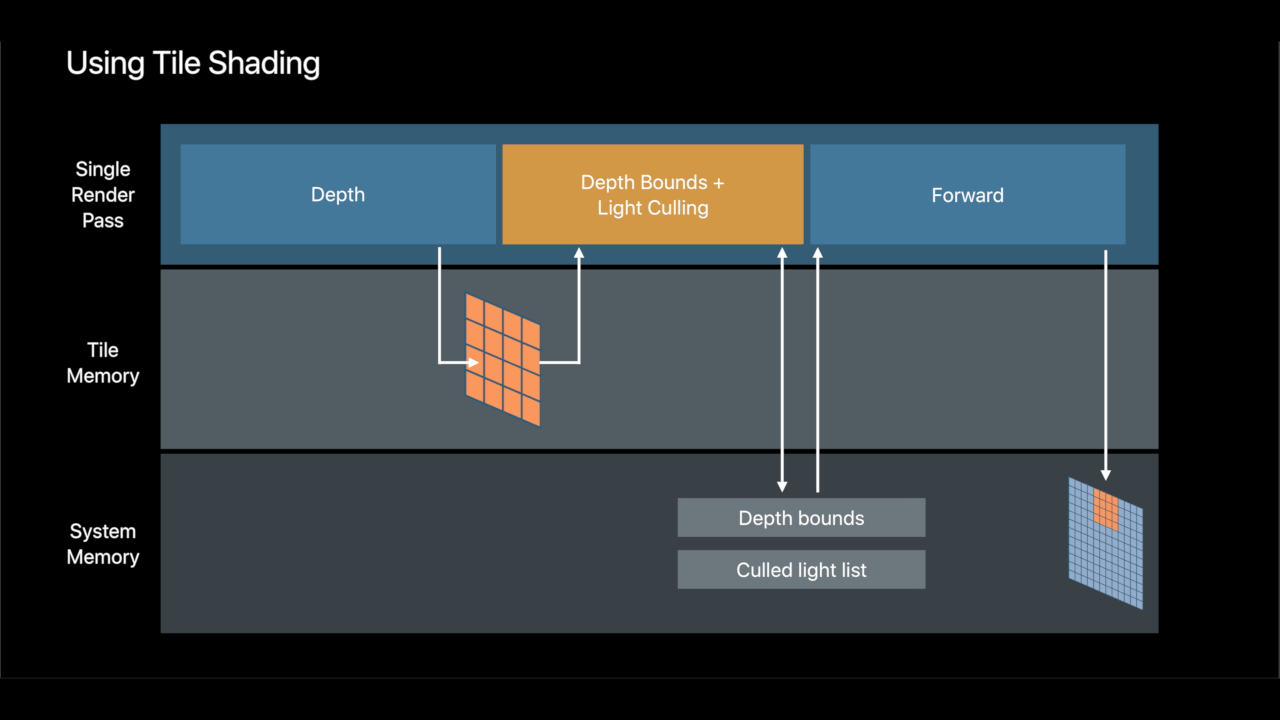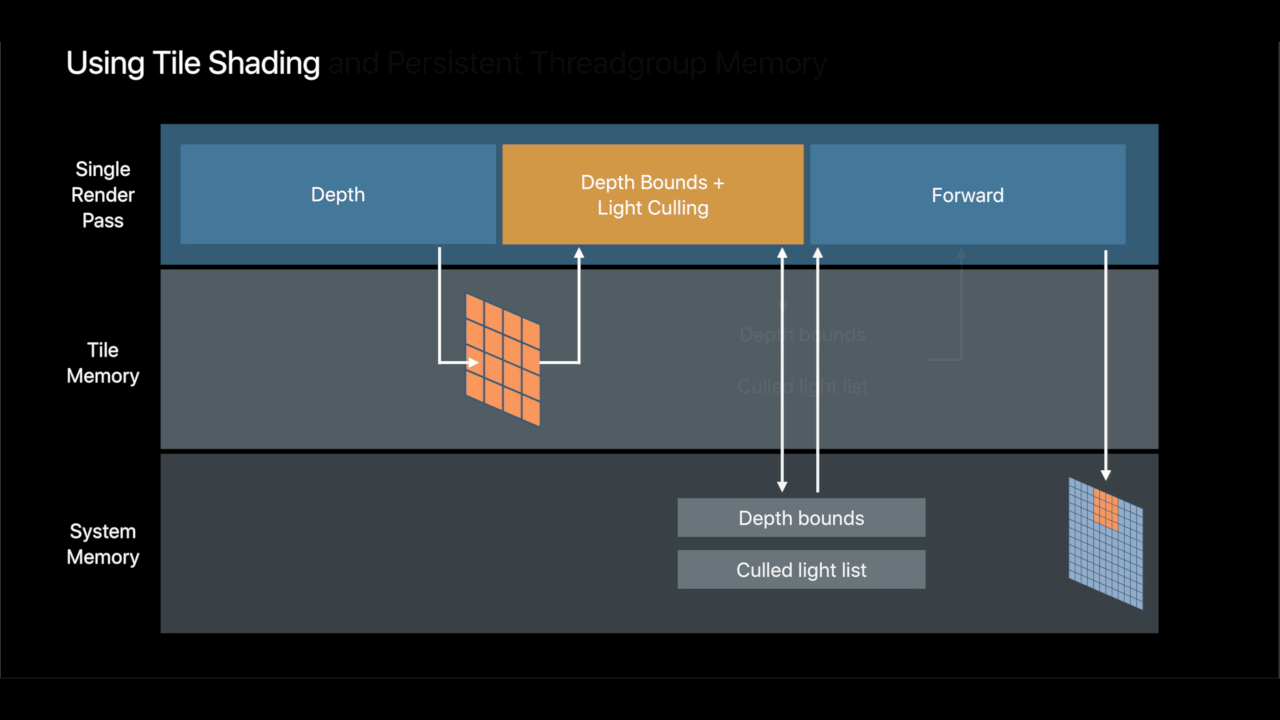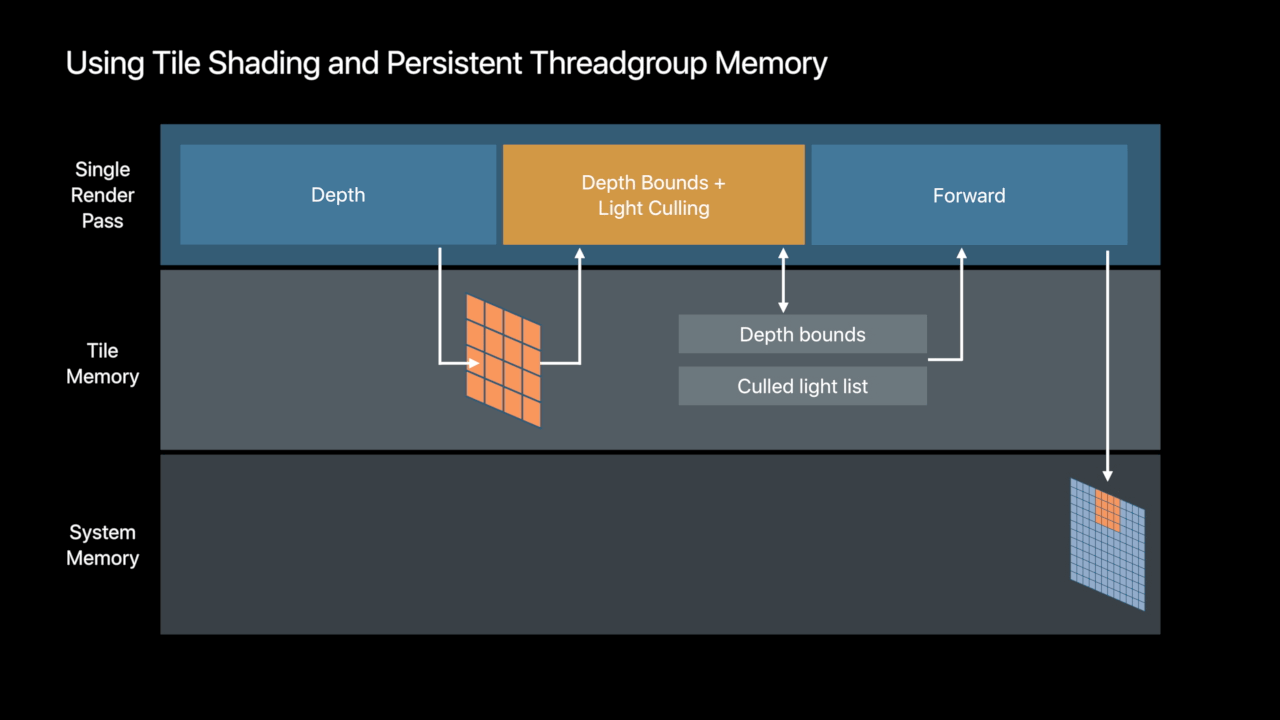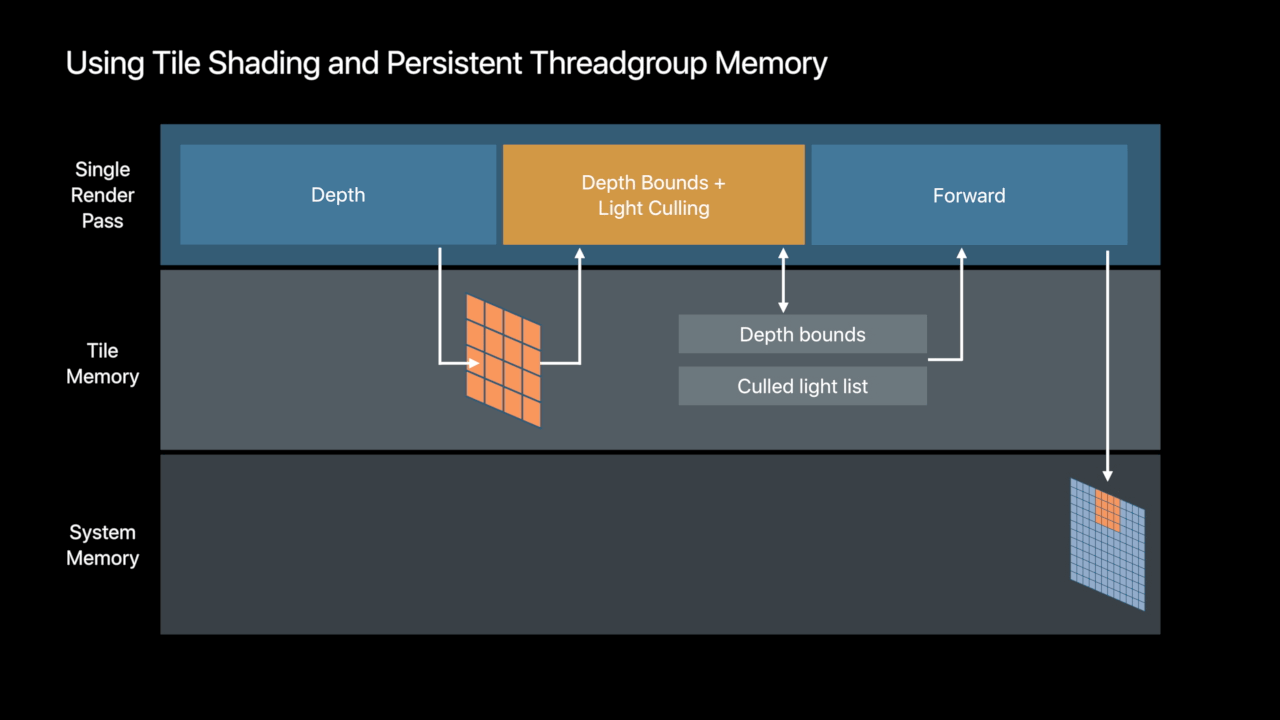
Persistent Threadgroup Memory
- Threadgroup memory available to render passes
- Available to fragment and tile shaders
- Buffer contents persistent for the lifetime of tile - Share data across pixels
- Communicate tile-scoped data between draws and tile dispatches
Tile Foraward Shading
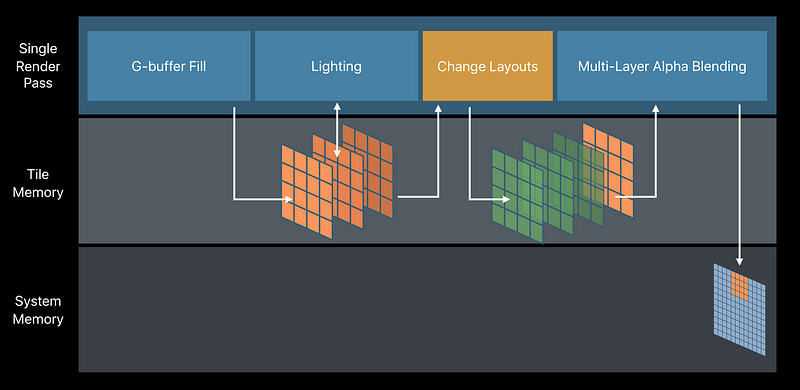
Deferred Shading and Multi-Layer Alpha Blending
With changing Imageblocks requires Tile Shading
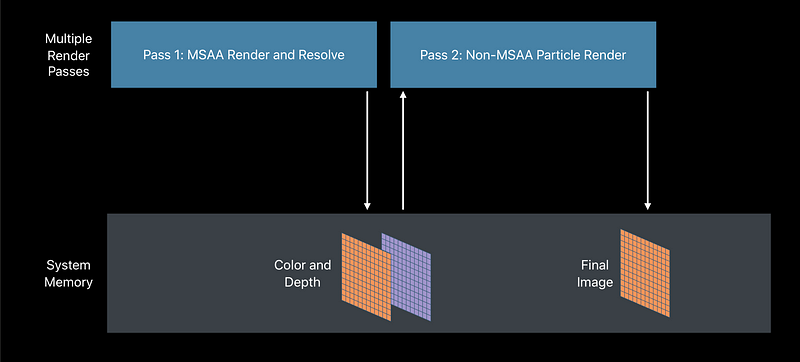
Multi-Sample Color Coverage Control
- MSAA is efficient on A-series GPUs
- Samples stored in tile memory for fast blending and resolves - MSAA is more efficient on A11
- Track unique colors in a pixel - Tile shading gives control over color overage
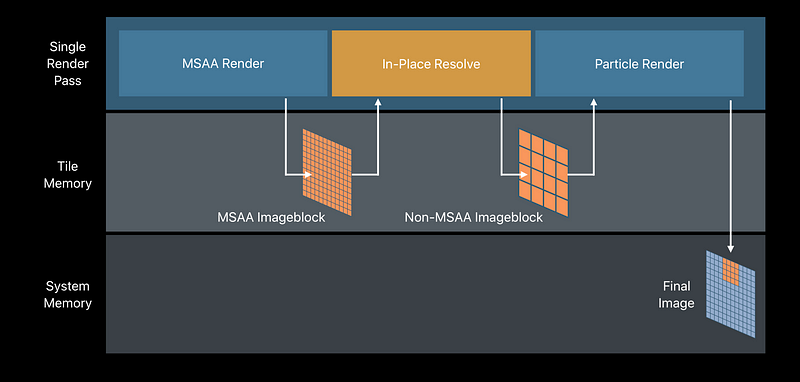
- Resolve in-place, in fast tile memory
Multi-Sample Rendering with Transparent Particles

Fortnite: Battle Royale
Shipping an Unreal Engine 4 console game on iOS with Metal
- Technical Chanllenges
- one map, larger than 6km²
- Time-of-day, destruction, player-built structures
- 100 players
- 50,000+ replicating actors
- Crossplay with console and desktop players
One Game, All Platforms
- Crossplay means we are limited in out ability to scale down the game
- If it affects gameplay, we can’t change it
- If a player can hide behind an object, we must render it

Metal
- Draw call performance allows us to render complex scenes with 1000 of dynamic objects
- Access to hardware features, e.g. programmable blending, allows for big wins on the GPU
- Feature set lets us support artist authored materials, physically based rendering, dynamic lighting and shadows, GPU particle simulation
Rendering Features Used on iOS
- Movable directional light with cascaded shadow maps
- Movable skylight
- Physically based matrials
- HDR and Tonemapping
- GPU particle simulation
- Artist authored materials with vertex animation

Scalability
- Scalability across platforms
- Minimum LOD for meshes
- Character LODs, animation update rates, etc. - Define 3 performance buckets, assigned devices based on performance
- Low (iPhone 6s, iPad Air 2, iPad min 4)
- Mid (iPhone 7, iPad Pro)
- High (iPhone 8, iPhone X, iPad Pro 2nd Gen)
Resolution
- Backbuffer resolution is what the UI renders at, determined by contentScaleFactor
- 3D resolution is separate, upscaled before rendering UI (adds some cost)
- Preferred scaling backbuffer, only scaled 3D separately on iPhone 6s, iPad Air 2, and iPad (5th gen)
- Tuned per-device
Shadows
Dynamic shadows have a large impact on both GPU and CPU performance

Foliage
Grass and foliage scale; both density and cull distance

Memory
- Memory doesn’t always correlate with performace
- iPhone 8 has less physical memory than iPhone 7+ but is faster - Low memory devices
- No foliage, no shadows, 16k max GPU particles, reduced pool for cosmetics, reduced texture memory pool - High memory devices
- Foliage, shadows, 64k max GPU particles, increased pool for cosmetics, increased texture memory pool
Memory Optimizations

Framerate Targets
- 30fps at the highest visual fidelity possible
- However Maxing out the CPU and GPU generates heat which causes the device to downclock.
We also want to conserve battery life
So we target 60fps for the environment but vsync at 30 fps
Performance Tracking
- Capture environment performance at a selection of POIs over time
- Daily 100 player playtests to capture dynamic performance
- Key performance stats tracked
- Instrumented profiles gathered from one device
- Replays saved off for later investigation
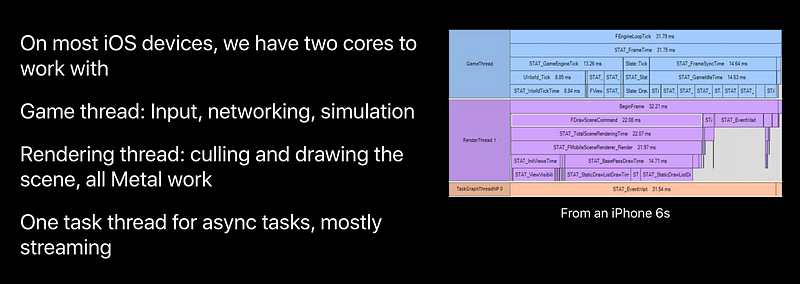
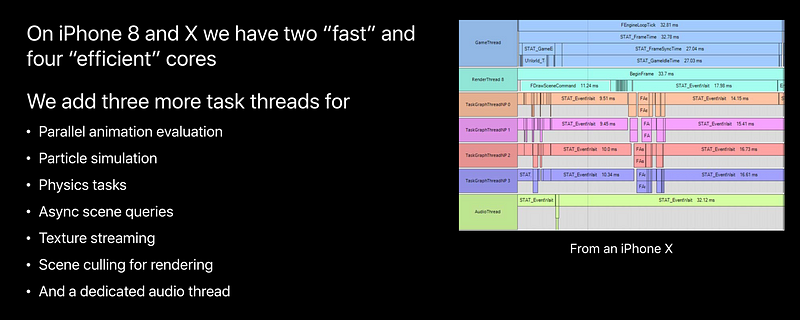
Threading
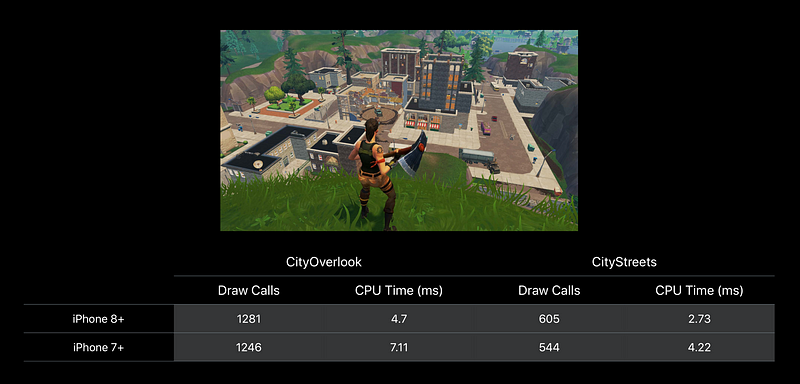
Draw Calls
- Draw calls were our main performance bottleneck
- Metal’s performance really helped here, 3–4x faster than OpenGL, allowed us to ship without more aggressive work to reduce draw calls
- Pulled in cull distance on decorative objects
- Added HLODs to combine draw calls
Hierarchical LOD
- Combine draw calls for a group of meshes
- Allow us to render the entire map while skydiving
- Even on the ground, POIs are visible from up to 2km away
- Added mid-range HLODs to further reduce draw calls in complex scenes like Tilted Towers
Pipeline State Objects
- Minimize how many are created at runtime to prevent hitching
- Follow best practives
- Compile functions offline
- Build library offline
- Group functions into a single library you can ship with your game - Ideally create all of the PSOs you need at load time
- What if the set of PSOs you might need is large?
- Artist authored shaders x Lighting scenarios x RT formats x MSAA x Stencil state (e.g. LOD dithering) x Input layout x Scalability level x and more - Minimize permutations where you can!
- Sometimes a dynamic branch is fine - Identity the most common subset you are likely to need and create those at load
- We use automation to run the game and gather PSOs used by device across the map, load cosmetics, fire weapons, etc.
- We also store PSOs created during daily playtests
- Not perfect, but…
- Number of PSOs created during gameplay is in the single digits on average
- We only create a small subset of the permutation matrix on load
Resource Allocation
- Creating resources on the fly can hitch due to streaming or creation of dynamic objects
- Treat resource allocation like memory allocation and use the same strategies to minimize “malloc” and “free”
- We use a binned allocation strategy for smaller allocations
Programmable Blending
- Optimization to reduce the number of resolves and restores for features that need to read the depth buffer, e.g. decals and soft particle blending
- During forward pass, write linear depth to alpha channel (we render to FP16 render target)
- During decal and translucent passes, if needed, read [[ color(0) ]] .a as linear depth
- MSAA resolve happens before postprocessing and tonemapping
- Bilinear filtering of HDR values can lead to very aliased edges, e.g. dark ceiling in shadow against a bright sky

Solution
Use programmable blending for the pre- tonemap pass to avoid resolving the MSAA color buffer to memory!
- Pre-tonemap before resolve
- Perform the normal MSAA resolve
- The first postprocessing pass reverses the “pre-tonemap”

Parallel Rendering
- On macOS we generate command buffers in parallel
- Not using parallel command encoders right now, separate command buffers easier to integrate in existing parallel rendering architecture
- Parallel command encoders would be needed on iOS - Experiment with parallel rendering on iOS
- For example, rendering thread on fast core versus four encoding threads on efficient cores
Metal Heaps
- Use MTLHeap instead of buffer sub-allocation
- Would also reduce hitches due to texture streaming
- Requires precise fences, particularly which stages read which resources
- Full barriers between passes underutilize the GPU
- Requires some rework of our rendering architecture to make this
bulletproof